

Yazar: Suden Çağlan Duran
Danışman: Prof. Dr. Rüya Şamlı
ÖNSÖZ
Küresel iklim değişikliğinin etkilerinin her geçen gün daha çok hissedildiği bir dünya düzeninde, su kaynaklarının korunması ve sürdürülebilir yönetimi kritik bir öneme sahiptir. Su kaynaklarının sınırlı olması ve artan ihtiyaçlar, bu projeyi tercih etmemizde etkili olmuştur. Projemiz, su kaynaklarının varlığının önemi konusunda farkındalık yaratmayı ve iklim değişikliği ile ilgili tedbirlerin alınmasını teşvike etmeyi amaçlamaktadır. Bu çalışma, yapay zeka ve veri analitiğinin güçlü yönlerini kullanarak bölgesel çözümler sunmayı ve sürdürülebilir bir geleceğe katkı sağlamayı hedeflemektedir.
Bu proje boyunca emeği geçen ve bizlere destek veren kişi ve kurumlara teşekkür etmeyi bir borç biliriz.
Bu projede kullanılan meteorolojik veri setlerinin sağlanmasına olanak tanıyan ECMWF (European Centre for Medium-Range Weather Forecasts) ve Copernicus Climate Data Store platformlarına teşekkür ederiz. Ek olarak, açık erişimli iklim verileri ve literatür kaynakları aracılığıyla çalışmamıza katkı sunan tüm bilimsel topluluklara katkıları için minnettarlığımızı ifade ederiz.
Ayrıca, bilgi ve deneyimleriyle bize yol gösteren, projemizin her aşamasında desteğini esirgemeyen değerli danışman hocamız Sayın Prof. Dr. Rüya Şamlı’ya teşekkür ederiz. Kendisi, bu çalışmanın başarıya ulaşmasında önemli bir rol oynamıştır.
Son olarak, bize her zaman destek olan ailelerimize, sabırları ve cesaretlendirici yaklaşımlarıyla bu projenin tamamlanmasında sağladıkları katkı için sonsuz teşekkürlerimizi sunarız. Onların desteği olmadan bu çalışmanın tamamlanması mümkün olmazdı.
Bu çalışmanın, iklim değişikliğinin su kaynaklarına etkileri konusunda bilimsel bir katkı sağlaması ve gelecek nesillere daha yaşanabilir bir dünya bırakma hedefimize katkıda bulunmasını temenni ederiz.
Saygılarımla,
Suden Çağlan Duran
İÇİNDEKİLER
ÖNSÖZ
İÇİNDEKİLER
ŞEKİL LİSTESİ
TABLO LİSTESİ
SEMBOL LİSTESİ
KISALTMA LİSTESİ
ÖZET
SUMMARY
- GİRİŞ
1.1 LİTERATÜR TARAMASI
1.2 PROJE ÖZGÜN YÖNLERİ - GENEL KISIMLAR
2.1 GRU (Gated Recurrent Unit) Kapılı Tekrarlayan Birim Modelleri
2.1.1 Uygulanan GRU Mimarileri
2.1.1.1 Temel (Hafif) GRU Mimarisi
2.1.1.2 Geliştirilmiş (Derin) Encoder-Decoder GRU Mimarisi
2.2 WaterNet-LSTM Modelleri
2.3 Değerlendirme Metrikleri
2.3.1 Mean Squared Error (MSE) – Ortalama Kare Hatası
2.3.2 Mean Absolute Error (MAE) – Ortalama Mutlak Hata
2.3.3 SMAPE – Simetrik Ortalama Mutlak Yüzde Hata
2.3.4 Root Mean Squared Error (RMSE) – Kök Ortalama Kare Hatası
2.4 WaterNet-LSTM Yöntemi
2.4.1 Modelin Yapısı ve Avantajları
2.4.2 Modelin Projeye Uygunluğu
2.4.3 Matematiksel Temeller
2.4.4 Modele Katkısı
2.4.5 Literatürdeki Kullanım Alanları
2.4.6 Literatürdeki Yaygın Yöntem Türleri ve İncelenmesi
2.5 Random Forest Regression (RFR)
2.5.1 Matematiksel Yapı
2.5.2 Literatürdeki Kullanımı
2.5.3 Projemizle İlgisi
2.6 Hybrid CNN-LSTM Modelleri
2.6.1 Model Yapısı
2.6.2 Literatürdeki Kullanımı
2.6.3 Projemizle İlgisi
2.7 Extreme Learning Machine (ELM)
2.7.1 Literatürdeki Kullanımı
2.7.2 Projemizle İlgisi
2.8 Random Forest Regression (RFR)
2.9 Extreme Learning Machine (ELM)
2.10 Data Setler
2.10.1 Meteorolojik Veriler
2.10.1.1 t2m (2 metre hava sıcaklığı)
2.10.1.2 d2m (2 metre çiğ noktası sıcaklığı)
2.10.1.3 tp (Total precipitation – Toplam yağış)
2.10.1.4 swvl1 (Toprak nemi – Seviye 1)
2.10.2 Türetilmiş Değişken – VPD (Vapor Pressure Deficit, Buhar Basıncı Açığı)
2.9 WEB ARAYÜZÜ TEKNOLOJİLERİ
2.9.1 React
2.9.2 Vite
2.9.3 SVG (Scalable Vector Graphics)
2.9.4 JSON ve PapaParse
2.9.5 Recharts - KULLANILAN ARAÇ VE YÖNTEM
3.1 Kullanılan Donanım
3.2 Kullanılan Yazılım ve Çevrimiçi Araçlar
3.2.1 Google Servisleri
3.3 Gerçekleştirme Ortamı
3.3.1 Çalışma Ortamı
3.3.2 Veri Depolama
3.4 Eğitilecek Modeller
3.5 Projenin Akış Diyagramı
3.6 Web Tabanlı Görselleştirme Sistemi
3.7 Kullanılan Kütüphaneler
3.7.2 Pandas
3.7.3 Matplotlib & Seaborn
3.7.4 Scikit-learn
3.7.5 TensorFlow & Keras
3.7.6 Keras Tuner
3.7.7 xarray ve netCDF4 - SİSTEMİN GERÇEKLENMESİ
4.1 Veri Hazırlama ve Girdi/Çıktı Yapısı
4.2 Eksik Verilerin Analizi ve Temizlenmesi
4.3 Aykırı Değer (Outlier) Analizi
4.3.1 Temperature 2m (T2M)
4.3.2 Dewpoint 2m (D2M)
4.3.3 Total Precipitation (TP)
4.3.4 Soil Moisture (SWVL1)
4.3.5 Surface Solar Radiation (SSRD)
4.3.6 Aykırı Değer ve Eksik Değer Genel Değerlendirmesi
4.4 Özellik Seçimi ve Hedef Değişkenin Türetilmesi
4.4.2 Korelasyon Analizi ile Girdi Değişkenlerinin Belirlenmesi
4.4.3 Sonuç Olarak Seçilen Girdi Değişkenleri
4.5 Girdi ve Çıktı Yapısının Belirlenmesi, Ölçekleme ve Zaman Penceresi Oluşturma
4.5.1 Özellik Ölçekleme
4.5.2 Zaman Serisi Pencereleme (Sliding Window)
4.5.3 Girdi ve Çıktı Boyutları
4.6 Model Eğitimi
4.6.1 GRU Modelleri
4.6.1.1 Veri Yapısı ve Ön İşleme
4.6.2 Fast GRU Modeli
4.6.3 Enhanced GRU Modeli
4.6.3.1 Enhanced GRU Test Performansı (Ham VPD Değeri ile)
4.7 WaterNet-LSTM Modelleri
4.7.1 Veri Yapısı ve Ön İşleme
4.7.2 WaterNet-LSTM (Baseline)
4.7.2.1 Test Performansı (WaterNet Baseline)
4.7.3 WaterNet-LSTM (Tuned)
4.7.3.1 Test Performansı (WaterNet Tuned)
4.7.4 Karşılaştırmalı Model Performansları
4.7.5 Şehir Bazlı Model Çıktıları (2029 Tahminleri)
4.7.5.1 En yüksek kuraklığa sahip 10 şehir
4.7.5.2 En düşük kuraklığa sahip 10 şehir
4.7.5.3 Türkiye Geneli VPD görünümü
4.8 Model Grafiklerinin Yorumlanması
4.9 Web Tabanlı Görsel Sunum ve Kullanıcı Arayüzü - TARTIŞMA VE SONUÇ
KAYNAKLAR
EKLER
ÖZGEÇMİŞ
ŞEKİL LİSTESİ
Şekil 2.4.1: LSTM tabanlı sel tahmin modeli yapısı
Şekil 2.4.2: 7-günlük tahmin grafiği. Kaynak: SpringerOpen (2023)
Şekil 2.4.3: WaterNet-LSTM modelinin farklı veri girdileri ile suyla ilgili süreçlerini gösteren diyagram
Şekil 2.4.5: Harita Bazlı Analiz
Şekil 2.10.1: Meteorolojik Veriler
Şekil 2.10.2: VPD’nin Bilimsel Formülü
Şekil 3.5: Projenin Akış Diyagramı
Şekil 4.1: Veri Kaynağı ve Boyutlar
Şekil 4.2: Eksik Verilerin Haritadaki Dağılımı
Şekil 4.3.1: T2M Outlier Analizi
Şekil 4.4.2: Girdi değişkenleri arasındaki Pearson korelasyonlarını gösteren ısı haritası
Şekil 4.5.3: Girdi ve Çıktı Boyutları
Şekil 4.6.2: Fast GRU Modeli Test Sonuçları
Şekil 4.6.3: Enhanced GRU Performance
Şekil 4.7.2: Test Metrics
Şekil 4.7.3: Gerçek VPD vs Tahmin Edilen
Şekil 4.7.3.1: Test Performansı Tuned vs Baseline
Şekil 4.7.5: Şehir Bazlı Model Çıktıları
Şekil 4.7.5.1: En yüksek kuraklığa sahip 10 şehir
Şekil 4.7.5.2: En düşük kuraklığa sahip 10 şehir
Şekil 4.7.5.3: Türkiye Geneli Kuraklık
Şekil 5.4.1: Web Tabanlı Kuraklık Haritası Arayüzü
TABLO LİSTESİ
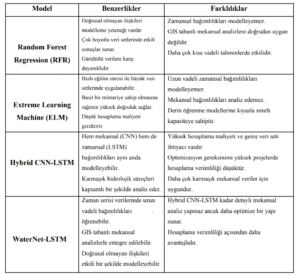
Tablo 3.3: Modeller arasındaki fark ve benzerlikler
Tablo 4.6.2: Enhanced GRU test tablosu
Tablo 4.6.3.1: Test performansı (Ham VPD değeri ile)
Tablo 4.7.2.1: Test performansı (Baseline)
Tablo 4.7.3.1: Test performansı (Tuned)
Tablo 4.7.3.2: Modellerin ortalama test performans karşılaştırması
SEMBOL LİSTESİ
VPD – Vapor Pressure Deficit (Buhar Basıncı Açığı)
t₂m – 2 metre sıcaklığı (°C veya K)
d₂m – 2 metre çiğ noktası sıcaklığı (°C veya K)
tp – Toplam yağış (m)
swvl1 – Toprak nemi (Soil Water Volumetric Level 1, m³/m³)
ssrd – Yüzeye gelen kısa dalga radyasyon (J/m²)
MAE – Mean Absolute Error (Ortalama Mutlak Hata)
RMSE – Root Mean Square Error (Kök Ortalama Kare Hata)
SMAPE – Symmetric Mean Absolute Percentage Error (Simetrik Ortalama Mutlak Yüzde Hatası)
R² – Determinasyon Katsayısı (Modelin açıklayıcılık gücü)
GRU – Gated Recurrent Unit (Kapılı Tekrarlayan Birim)
LSTM – Long Short-Term Memory (Uzun Kısa Süreli Bellek Ağı)
ERA5 – Avrupa Orta Vadeli Hava Tahminleri Merkezi’nin (ECMWF) 5. nesil iklim veri kümesi
MinMax – Minimum-Maksimum Normalizasyonu
KISALTMA LİSTESİ
AI – Artificial Intelligence (Yapay Zeka)
ML – Machine Learning (Makine Öğrenimi)
MGM – Meteoroloji Genel Müdürlüğü
TÜİK – Türkiye İstatistik Kurumu
SVR – Support Vector Regression (Destek Vektör Regresyonu)
GIS – Geographic Information System (Coğrafi Bilgi Sistemi)
LSTM – Long Short-Term Memory (Uzun Kısa Süreli Bellek)
PCA – Principal Component Analysis (Ana Bileşen Analizi)
MSE – Mean Squared Error (Ortalama Kare Hatası)
R² – R-Squared (Determinasyon Katsayısı)
ÖZET
KÜRESEL İKLİM DEĞİŞİKLİĞİ VE SU KAYNAKLARININ YÖNETİMİ
Küresel iklim değişikliği, nüfus artışı ve artan su talebi, su kaynaklarının sürdürülebilir bir şekilde yönetilmesini hem ulusal hem de küresel ölçekte kritik bir mesele haline getirmiştir. Bu kapsamda, iklim verilerine dayalı olarak kuraklık tahminleri yapabilen karar destek sistemlerinin geliştirilmesi, su yönetimi politikalarının oluşturulmasında stratejik bir önem taşımaktadır. Bu çalışmada, Türkiye’nin 81 ili için şehir bazlı kuraklık tahmini yapabilen bir sistem geliştirilmiş; bu sistem, makine öğrenimi temelli modeller ile uzun vadeli VPD (Vapor Pressure Deficit – Buhar Basınç Açığı) tahminlerine dayanmaktadır.
Çalışmada 2015–2024 yılları arasındaki saatlik iklim verileri ERA5 ve Copernicus Climate Data Store üzerinden elde edilmiştir. Veriler Türkiye’nin kara sınırları içerisindeki grid noktalarına indirgenmiş ve eksik veriler temizlenerek analiz için uygun hale getirilmiştir. Aykırı değerler çıkarıldıktan sonra değişkenler yıllık ortalamalara çevrilmiş, MinMax ölçekleme uygulanmış ve korelasyon analiziyle öznitelik seçimi yapılmıştır. Temel meteorolojik girdiler olarak sıcaklık (t2m), çiğ noktası sıcaklığı (d2m), yağış miktarı (tp), yüzey nemi (swvl1) ve güneşlenme süresi (ssrd) kullanılmıştır. Bu verilerle VPD değeri türetilmiş ve hedef değişken olarak modellenmiştir.
Tahmin sürecinde iki farklı derin öğrenme mimarisi karşılaştırılmıştır: WaterNet-LSTM ve GRU. WaterNet-LSTM mimarisi, fine-tuning yöntemiyle proje verilerine uyarlanarak denenmiş; ancak daha düşük hata oranları ve daha kısa eğitim süresi ile GRU mimarisi daha başarılı bulunmuştur. Geliştirilmiş GRU modeli, test verisi üzerinde SMAPE: %19.90, RMSE: 0.0755 ve MAE: 0.0454 gibi başarılı sonuçlar üretmiştir. Böylece GRU, Türkiye genelindeki şehirler için VPD tahmininde daha uygun bir model olarak seçilmiştir.
Model çıktıları, kuraklık düzeyine göre “düşük”, “orta” ve “yüksek” risk kategorilerine ayrılmış ve görselleştirilmiştir. Sonuçlar, React ve JavaScript teknolojileri kullanılarak geliştirilen bir web uygulamasında sunulmuştur. Kullanıcılar, şehir haritası üzerinden istedikleri ili seçerek o şehir için önümüzdeki 5 yılın VPD tahminine ve kuraklık düzeyine erişilebilmektedir.
Bu çalışma, zamansal analizler için GRU gibi hafif ve etkili modellerin VPD gibi karmaşık iklim göstergeleri üzerinde başarılı öngörüler sağlayabileceğini ortaya koymuştur. Model, sürdürülebilir su yönetimi politikalarına bilimsel altyapı sağlayabilecek nitelikte bir erken uyarı sistemi potansiyeli taşımaktadır. Ayrıca, modelin web arayüzü ile entegre edilmesi sayesinde yerel yönetimlerin ve karar vericilerin bu tahminleri aktif biçimde kullanmaları mümkün hale gelmiştir.
SUMMARY
GLOBAL CLIMATE CHANGE AND WATER RESOURCE MANAGEMENT
Global climate change, population growth, and increasing water demand have made the sustainable management of water resources a critical issue on both national and international scales. In this context, the development of decision support systems capable of predicting drought based on climate data plays a strategic role in shaping water management policies. This study presents a system designed to estimate drought levels based on city-level forecasts of the Vapor Pressure Deficit (VPD) across all 81 provinces of Turkey, utilizing machine learning-based models for long-term forecasting.
Hourly climate data between 2015 and 2024 were obtained from ERA5 and Copernicus Climate Data Store. The raw data were filtered to include only the grid points covering Turkey’s landmass. After handling missing values and removing outliers, the variables were converted to yearly averages. A MinMax scaler was applied, and feature selection was conducted using correlation analysis. The selected meteorological input variables include air temperature (t2m), dew point temperature (d2m), total precipitation (tp), soil moisture (swvl1), and surface solar radiation (ssrd). The VPD variable, representing the difference between saturated and actual vapor pressure, was derived and used as the target for forecasting.
Two deep learning architectures were implemented and compared: WaterNet-LSTM and GRU. The WaterNet-LSTM model was fine-tuned using the project’s local dataset but was outperformed by the GRU model in terms of both training efficiency and prediction accuracy. The enhanced GRU model achieved strong results on the test set, with SMAPE: 19.90%, RMSE: 0.0755, and MAE: 0.0454, thus making it the preferred choice for predicting VPD across Turkey.
The model outputs were categorized into three risk levels—low, medium, and high—based on the forecasted VPD values and visualized accordingly. These results were then presented through a web application developed using React and JavaScript. Users can interactively select a city from the map and access its 5-year VPD forecast along with a drought risk level.
This study demonstrates that lightweight and efficient models such as GRU can provide highly accurate predictions for complex climate indicators like VPD. Furthermore, the integration of the forecasting model with a user-friendly web interface enables local authorities and decision-makers to access and utilize drought risk assessments more effectively. The developed system shows great potential as an early warning tool and as a technical foundation for sustainable water resource planning in the face of climate variability.
1.GİRİŞ
Çalışmada su kaynaklarının sürdürülebilir yönetimi, artan nüfus, iklim değişikliği ve su kıtlığı gibi küresel sorunlar çerçevesinde ele alınmaktadır. Bu bağlamda, hidrolojik süreçlerin doğru tahmini ve kaynakların verimli kullanımı için makine öğrenimi ve derin öğrenme yöntemlerinin kullanımının önemi vurgulanmıştır. Literatürde, zaman serisi analizlerinden derin öğrenme modellerine kadar birçok farklı yöntemin su yönetiminde başarıyla uygulandığı gözlemlenmiştir. Ancak, bu yöntemler genellikle mekansal ve zamansal bağımlılıkları aynı anda modelleme konusunda sınırlamalara sahiptir ([1], [2], [3]).
Küresel ölçekte yaşanan kuraklık olayları, su kaynaklarının yalnızca daha az kullanılabilir hale gelmesine değil, aynı zamanda tarım, enerji üretimi ve halk sağlığı gibi pek çok sektörü de doğrudan tehdit etmektedir. Örneğin, 2022 yılında Avrupa genelinde yaşanan aşırı kuraklık, son 500 yılın en şiddetli su krizi olarak kayıtlara geçmiştir ([4]). Türkiye özelinde ise Güneydoğu Anadolu ve İç Anadolu bölgelerinde yıllık yağış oranlarının düşmesi, toprak nemi seviyelerinde ciddi azalmalar ve yer altı su rezervlerinde tükenmeye yakın eğilimler gözlemlenmiştir ([5]). Bu durum, su kaynaklarının yalnızca doğru izlenmesini değil, aynı zamanda geleceğe yönelik tahmin edilmesini de zorunlu hale getirmiştir.
Bu çalışmanın temel amacı, Türkiye’deki 81 il için şehir bazlı uzun vadeli kuraklık tahminleri yapabilecek bir sistem geliştirmektir. Geliştirilen sistem, geçmiş yıllara ait meteorolojik verilerden faydalanarak VPD (Vapor Pressure Deficit – Buhar Basıncı Açığı) gibi önemli iklimsel göstergeleri öngörmeyi hedeflemektedir. VPD, atmosferik nem talebi ile doğrudan ilişkili olması nedeniyle, özellikle tarımsal üretim ve su tüketim planlamasında kritik bir değişkendir ([6]). Modelleme sürecinde hem GRU (Gated Recurrent Unit) hem de WaterNet-LSTM gibi derin öğrenme temelli mimariler uygulanmış, bunların başarımı karşılaştırılmıştır. Literatürde önerilen birçok modelin, yerel veriyle test edilmediği ya da zamansal-mekansal analizleri aynı anda gerçekleştiremediği göz önünde bulundurularak, bu çalışmada yerel veriye uyarlanmış, çoklu model karşılaştırmalı bir yapı benimsenmiştir.
Geliştirilen tahmin sistemi, yalnızca bilimsel analizler sunmakla sınırlı kalmamış, aynı zamanda elde edilen verileri yerel yöneticiler ve kamuoyu tarafından erişilebilir kılacak şekilde web tabanlı bir arayüzle desteklenmiştir. Bu arayüz aracılığıyla kullanıcılar, Türkiye haritası üzerinde diledikleri şehri seçerek, ilgili ilin önümüzdeki beş yıla ait tahmini kuraklık eğilimlerini inceleyebilmektedir. Böylece sistem, akademik katkı sağlamanın ötesinde, karar destek mekanizmalarına, sürdürülebilir kaynak yönetimine ve iklim farkındalığına hizmet eden pratik bir araç haline getirilmiştir.
1.1 LİTERATÜR TARAMASI
Günümüzde su kaynaklarının verimli kullanımı ve sürdürülebilir yönetimi doğrultusunda geliştirilen çok sayıda model ve sistem bulunmaktadır. Bu sistemlerin bazıları geleneksel istatistiksel yöntemlere dayanırken, bazıları ise makine öğrenmesi ve derin öğrenme gibi yapay zeka tabanlı yaklaşımlar kullanmaktadır.
Örneğin Breiman tarafından geliştirilen Random Forest Regression (RFR) algoritması, değişkenler arası ilişkileri güçlü şekilde yakalayarak su seviyesi ve yağış-akış ilişkisi gibi problemleri yüksek doğrulukla modelleyebilmektedir [57]. Ancak bu yöntem zamansal bağımlılıkları doğrudan ele almadığı için kuraklık gibi zaman serisi temelli olaylarda yetersiz kalabilmektedir.
Buna karşın Extreme Learning Machine (ELM) modeli, hızlı eğitimiyle öne çıkmakta ve bazı çalışmalarda akarsu debisi tahmini gibi görevlerde başarıyla uygulanmıştır [58]. Ancak ELM de sekansiyel bilgi işleme kapasitesine sahip olmadığından, VPD gibi zamana duyarlı değişkenlerde sınırlı kalmaktadır.
Son yıllarda derin öğrenme temelli melez yaklaşımlar dikkat çekmektedir. Örneğin CNN-LSTM mimarisi, mekânsal örüntü tanıma (CNN) ile zamansal bağımlılıkların (LSTM) birlikte modellenmesini sağlamaktadır. Zhang ve arkadaşlarının yürüttüğü bir çalışmada CNN-LSTM-Attention yapısının beş farklı havzada günlük akış tahmininde %90’a varan başarı sağladığı rapor edilmiştir [59]. Ancak bu tür modellerin eğitimi için yüksek işlem gücü ve büyük veri setleri gerekmektedir, bu da kırsal bölgelerdeki uygulamalar için bir dezavantaj oluşturmaktadır.
Daha optimize bir alternatif olarak Gated Recurrent Unit (GRU) modelleri kullanılmaktadır. GRU, LSTM’ye kıyasla daha az parametreye sahip olması sayesinde daha hızlı eğitilmekte ve küçük veri setlerinde daha kararlı performans sunmaktadır. GRU tabanlı sistemler, kuraklık gibi ardışık iklimsel değişkenlerin öngörülmesinde yaygın olarak tercih edilmektedir [60].
Bu modellere ek olarak son yıllarda açıklanabilir yapay zeka uygulamaları ön plana çıkmıştır. Özellikle WaterNet mimarisi, klasik LSTM yapısının fiziksel su döngüsü bileşenleriyle uyumlu hale getirilmiş hâlidir. Yapay sinir ağlarının her bir bileşeni, su havzasındaki rezervuarları temsil eder biçimde kurgulanmıştır. Bu yapı sayesinde modelin çıktıları hidrolik süreçlerle ilişkilendirilebilir hâle gelmiş, böylece “kara kutu” eleştirileri azaltılmıştır [61]. WaterNet, daha az veriyle yüksek doğruluk sunmasıyla dikkat çekmektedir.
Türkiye özelinde yapılan çalışmalarda da benzer yaklaşımlar gözlemlenmektedir. Kaya (2025), Köprüçay havzasında gerçekleştirdiği çalışmada RFR algoritmasının diğer klasik yöntemlere göre daha başarılı sonuçlar verdiğini göstermiştir [62]. Yine ülkemizde gerçekleştirilen bazı çalışmalarda GRU tabanlı derin öğrenme mimarilerinin yağış ve sıcaklık verileriyle yüksek başarıda tahminler üretebildiği bildirilmiştir.
Tüm bu örnekler, derin öğrenme temelli modellerin özellikle uzun vadeli kuraklık tahminleri ve şehir bazlı risk analizleri açısından avantaj sunduğunu göstermektedir. Bu çalışmada da bu güçlü yönlerden faydalanılarak, hem GRU hem de WaterNet-LSTM mimarileri kullanılarak Türkiye’deki 81 şehir için VPD tahmini yapılmış ve bunlar kullanıcı dostu bir web arayüzü ile sunulmuştur. Böylece literatürdeki zayıf yönlere (yüksek hesaplama maliyeti, yorumlanabilirlik eksikliği, lokal veri eksikliği) doğrudan çözüm sunulması hedeflenmiştir.
1.2. PROJE ÖZGÜN YÖNLERİ
Bu proje, mevcut kuraklık tahmin sistemlerinin yerel ölçekte yeterince özelleştirilememesi, yorumlanabilirliğinin düşük olması ve kullanıcıya doğrudan karar desteği sağlayamaması gibi önemli eksikliklere çözüm üretmeyi hedeflemektedir. Şehir bazlı VPD (Vapor Pressure Deficit) tahmini üzerine inşa edilen bu sistem, hem geçmiş iklim verilerini hem de derin öğrenme algoritmalarını bir araya getirerek 81 il için uzun vadeli su kıtlığı öngörüleri sunmaktadır.
Projenin en özgün yönlerinden biri, klasik LSTM modellerinin yorumlanamaz yapısına karşın, fiziksel süreçlerle açıklanabilirliği artırılmış GRU ve WaterNet-LSTM mimarilerinin karşılaştırmalı olarak kullanılmasıdır. Böylece hem yüksek doğruluk sağlanmakta, hem de model çıktıları karar vericiler tarafından anlamlı bir şekilde yorumlanabilmektedir. Ayrıca sistemin eğitimi, sadece hazır veri setleriyle değil, aynı zamanda geçmiş yıllara ait yerel meteorolojik verilerle zenginleştirilerek gerçekleştirilmiştir. Bu yaklaşım, tahminlerin sahaya özgü hale gelmesini sağlayarak literatürdeki genellenebilirlik sorununa önemli bir katkı sunmaktadır.
Bununla birlikte proje, sadece bilimsel analiz üretmekle kalmayıp, geliştirilmiş web tabanlı arayüzü sayesinde karar destek sistemine dönüşmektedir. Kullanıcılar Türkiye haritası üzerinden istedikleri şehre tıklayarak, ilgili bölgeye ait gelecek 5 yıllık kuraklık eğilimini kolayca görüntüleyebilmekte ve bu sayede yerel yönetimler ile çiftçiler gibi farklı paydaşlar için pratik ve sezgisel bir kullanım sunulmaktadır.
Tüm bu unsurlar birleştiğinde proje; düşük maliyetle uygulanabilirliği, açık model mimarisi ve kullanıcı odaklı görselleştirme altyapısıyla, hem kamu politikaları hem de sürdürülebilir su yönetimi açısından yenilikçi ve bütünsel bir çözüm sunmaktadır
2.GENEL KISIMLAR
Bu bölümde, çalışmamızda kullanılan yöntemler, algoritmalar ve veri setleri hakkında temel bilgiler sunulacaktır. Ayrıca, giriş bölümünde referans gösterilen benzer çalışmalarda kullanılan tekniklerin açıklamaları da yer alacaktır. Bu sayede, çalışmamızda kullanılan yöntemlerin teorik altyapısı detaylandırılacak ve proje bağlamında nasıl uygulandığı anlaşılabilir hale gelecektir.
2.1 GRU (Gated Recurrent Unit) Kapılı Tekrarlayan Birim Modelleri
GRU, RNN (Recurrent Neural Network, Tekrarlayan Sinir Ağları) mimarisine dayanan ve özellikle zamansal bağımlılık gösteren verilerle yapılan tahminlerde etkin performans gösteren bir yapay sinir ağı türüdür. Projede hem temel hem de geliştirilmiş GRU modelleri uygulanmıştır. GRU mimarisi, düşük parametre sayısı ve hesaplama verimliliği sayesinde eğitim sürecinde avantaj sağlamıştır.
Model, geçmiş 10 yılın meteorolojik verilerinden faydalanarak, takip eden 5 yılın VPD (Vapor Pressure Deficit) değerlerini tahmin etmek üzere eğitilmiştir. GRU mimarisi ile elde edilen sonuçlar, düşük RMSE (Kök Ortalama Kare Hatası) ve MAE (Ortalama Mutlak Hata) değerleriyle yüksek doğruluk oranlarına ulaşmıştır.
2.1.1 Uygulanan GRU Mimarileri
2.1.1.1 Temel (Hafif) GRU Mimarisi
Bu model, sade bir encoder yapısıyla inşa edilmiştir. Girdi olarak geçmiş 10 yıla ait meteorolojik verileri alır ve takip eden 5 yılın VPD değerlerini doğrudan tahmin eder. Yapısında yalnızca tek bir GRU katmanı bulunur ve tahmin çıktıları tek adımda elde edilir. Basit yapısı sayesinde hızlı eğitim ve düşük hesaplama maliyeti avantajı sunar. Zaman serisi problemleri için etkili bir başlangıç mimarisi olarak kullanılmıştır.
2.1.1.2 Geliştirilmiş (Derin) Encoder-Decoder GRU Mimarisi
Bu mimaride, encoder ve decoder olmak üzere iki aşamalı bir yapı tercih edilmiştir. Encoder kısmı, geçmiş yılların zaman serisi bilgisini özetlerken, decoder kısmı bu bilgiyi kullanarak ardışık şekilde 5 yıllık VPD tahmini üretir. Mimari, birden fazla GRU katmanı içerebilir ve daha iyi genelleme performansı için dropout katmanlarıyla desteklenmiştir. Bu yapı, daha karmaşık zaman bağımlılıklarını öğrenmeye olanak sağlar ve uzun vadeli tahminlerde tercih edilmiştir.
2.2 WaterNet-LSTM Modelleri
WaterNet-LSTM, klasik LSTM mimarisinin üzerine inşa edilmiş ve konvolüsyonel özellik çıkarımı ile zenginleştirilmiş bir zaman serisi tahmin modelidir. Özellikle hidrolojik modelleme ve su kaynakları yönetimi gibi alanlarda kullanılmak üzere geliştirilmiştir. Model, mekânsal ve zamansal bileşenleri birlikte değerlendirme kapasitesiyle öne çıkmaktadır.
Bu çalışmada, WaterNet-LSTM mimarisi iki farklı biçimde uygulanmıştır: ilki doğrudan kullanılan standart yapı, diğeri ise proje verilerine özgü hiperparametre ayarlarıyla yeniden yapılandırılmış fine-tuned versiyondur.
Model, geçmiş 10 yıla ait meteorolojik değişkenleri giriş olarak alır ve takip eden 5 yılın yıllık ortalama VPD değerlerini tahmin etmek üzere yapılandırılmıştır. Konvolüsyonel katmanlar, modelin giriş verilerinden mekânsal örüntüleri yakalamasını sağlarken; LSTM blokları zaman bağımlılıklarını öğrenir. Skip-connection (atlama bağlantıları) gibi yapılar, öğrenmenin daha derin katmanlarda sürdürülebilir olmasını ve bilgi kaybının azaltılmasını desteklemektedir. Modelin uç katmanlarında ise tam bağlantılı (fully connected) katmanlar yer almakta ve tahmin çıktıları bu katmanlar aracılığıyla üretilmektedir
2.3 Değerlendirme Metrikleri
Projede kullanılan regresyon modellerinin performansını değerlendirmek için aşağıdaki metrikler kullanılacaktır:
2.3.1 Mean Squared Error (MSE)-Ortalama Kare Hatası
MSE, tahmin edilen değerler ile gerçek değerler arasındaki farkların karesinin ortalamasını hesaplar. Bu metrik, tahmin hatasının büyüklüğünü ölçmek için kullanılır. MSE, daha düşük olduğunda modelin performansı daha iyi olarak değerlendirilir.
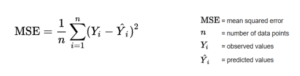
2.3.2 Mean Absolute Error (MAE) – Ortalama Mutlak Hata
MAE, tahmin edilen değerler ile gerçek değerler arasındaki farkların mutlak değerlerinin ortalamasını ölçer. Bu metrik, model hatalarını daha basit bir şekilde ifade etmek için kullanılır.
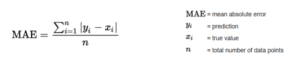
2.3.3 SMAPE – Simetrik Ortalama Mutlak Yüzde Hata
SMAPE, modelin tahmin performansını yüzde cinsinden ölçen simetrik bir hata metriğidir. Gerçek ve tahmin edilen değerler arasındaki mutlak farkın, bu iki değerin toplamına oranının ortalamasını alır. Böylece hem düşük hem de yüksek değerlerdeki hataları dengeli biçimde yansıtarak tahmin hatasını yüzde olarak ifade eder. SMAPE değeri 0’a yaklaştıkça modelin doğruluğu artar.
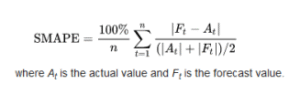
2.3.4 Root Mean Squared Error (RMSE) – Kök Ortalama Kare Hatası
MSE’nin karekökü alınarak hesaplanır ve hata boyutunu yorumlamak için daha kullanışlı hale getirilir. RMSE, tahmin edilen değerlerin gerçek değerlere ne kadar yakın olduğunu gösterir.
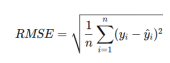
Bu metrikler, her bir modelin performansını farklı yönlerden incelemek için kullanılacaktır. Projenin gereksinimlerine bağlı olarak, özellikle MSE, SMAPE ve RMSE gibi metrikler tahmin doğruluğu ve hata oranlarını değerlendirmek için öncelikli olarak kullanılacaktır.
2.4 WaterNet-LSTM Yöntemi
LSTM modelleri, zaman serisi verilerinde uzun vadeli bağımlılıkları öğrenmek için tercih edilmektedir ([4]). Bu çalışmada 2 katman ve 64 nöron kullanımı, modelin öğrenme kapasitesini artırırken, hesaplama maliyetini optimum seviyede tutar ([5]). Öğrenme oranı olarak 0.001 seçilmesi, kararlı bir optimizasyon süreci sağlar ([6]). Dropout oranı (düşürme oranı) (%20) ise aşırı öğrenmeyi engellemek için yaygın bir yöntemdir ([7]). Eğitim süresi olarak 50 epoch belirlenmiş, bu değer literatürde genellikle küçük ve orta büyüklükteki veri setleri için önerilmektedir ([8])
WaterNet-LSTM, uzun kısa süreli bellek (Long Short-Term Memory, LSTM) modellerine dayalı olarak geliştirilen, hidrometeorolojik problemlerin çözümüne yönelik özel bir yapay zeka modelidir. LSTM modelleri, zaman serisi verilerindeki uzun vadeli bağımlılıkları öğrenme yeteneği sayesinde, özellikle su kaynaklarının yönetimi gibi karmaşık ve dinamik süreçlerin tahmin edilmesinde sıklıkla kullanılmaktadır ([15], [16])
2.4.1 Modelin Yapısı ve Avantajları
WaterNet-LSTM, geleneksel LSTM mimarisi üzerine inşa edilmiş olup, su döngüsündeki çeşitli dinamikleri modellemek için tasarlanmıştır. Bu model, özellikle
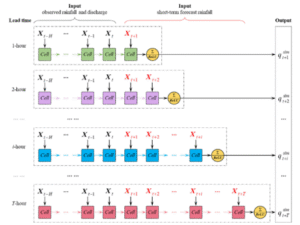
Şekil 2.4.1: LSTM tabanlı sel tahmin modeli yapısı
Zaman Serisi Verileriyle Çalışma Yeteneği:
LSTM’nin hücre yapıları, uzun vadeli bağımlılıkları ve kısa süreli ilişkileri etkili bir şekilde modelleyebilir. WaterNet-LSTM, bu yeteneği kullanarak su kıtlığı tahminlerinde yüksek doğruluk sağlamaktadır ([17]).
Hidrometeorolojik Süreçlere Özel Tasarım:
WaterNet, su döngüsü süreçlerini (yağış-akar ilişkileri, yeraltı suyu akışı vb.) yakından takip etmek ve analiz etmek için optimize edilmiştir. Model, bu süreçlere özel tasarımı sayesinde geleneksel makine öğrenimi algoritmalarına kıyasla daha iyi performans göstermektedir ([18]).
Çoklu Veri Kaynaklarını İşleyebilme:
WaterNet-LSTM, meteorolojik veriler (yağış, sıcaklık) ile hidrolojik veriler (su tüketimi, su akışı) gibi çoklu veri kaynaklarını entegre ederek kapsamlı bir analiz yapabilmektedir ([19]).
2.4.2 Modelin Projeye Uygunluğu
WaterNet-LSTM’nin seçilmesindeki temel gerekçelerinden biri, modelin su kıtlığı tahmini gibi hidrolojik süreçlerde literatürde kanıtlanmış başarısıdır. Literatürde, modelin hem doğrusal hem de doğrusal olmayan veri ilişkilerini etkili bir şekilde modelleyerek, özellikle az verili ya da dengesiz veri setlerinde başarılı sonuçlar ürettiği gösterilmiştir ([9]). Bunun yanı sıra, LSTM modellerinin genel yapısı, veri kayıplarının bulunduğu durumlarda bile sağlam tahminler yapmayı mümkün kılarak, su kaynakları yönetimi için kritik öneme sahip risk analizlerine katkı sağlar.
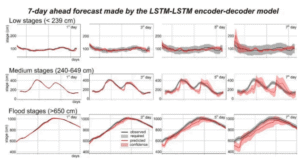
Şekil 2.4.2: 7-günlük LSTM tahmin grafiği
2.4.3 Matematiksel Temeller
LSTM’nin başarısının temelinde, girdilerin geçmiş zamandaki durumunu taşıyan bir gizli durum vektörü ve öğrenilen ağırlıklar yer alır. WaterNet-LSTM modeli, bu matematiksel temelleri kullanarak, su döngüsü süreçlerinde uzun vadeli bağımlılıkları şu şekilde öğrenir:

Bu matematiksel yapı, su kaynaklarının yönetimi ve su kıtlığı tahminlerinde etkin bir şekilde kullanılmaktadır. Modelin temel bileşenleri ve bu bileşenlerin projeye katkısı şu şekilde özetlenebilir:
WaterNet-LSTM modeli, meteorolojik (örneğin, yağış miktarı, sıcaklık ve nem oranı) ve hidrolojik (örneğin, su tüketimi) verileri giriş katmanında işlemektedir. Bu çeşitli veri kaynaklarının entegrasyonu, modelin su kaynaklarının durumu üzerindeki çok boyutlu etkileri daha iyi analiz edebilmesine olanak tanımaktadır.
Şekil 2.4.3: WaterNet-LSTM modelinin farklı veri girdileri ile suyla ilgili süreçlerini gösteren diyagram
LSTM hücreleri, verilerin geçmişteki durumlarını öğrenerek bu bilgiyi gelecekteki tahminlere dahil etmektedir. Model, su tüketimi ve meteorolojik değişkenler arasındaki zaman bağımlılıklarını analiz ederek gelecekteki su tüketimi ve kaynak durumu hakkında öngörülerde bulunabilmektedir. Bu yapı, özellikle iklim değişikliğine bağlı uzun vadeli etkilerin modellenmesinde etkili bir araç sunmaktadır.
WaterNet-LSTM modeli, belirli zaman dilimlerinde (örneğin, 7 gün sonrasına yönelik) su kaynaklarının miktarı ve kıtlık riski hakkında tahminlerde bulunur. Bu tahminler, modelin öğrenilen bağımlılıkları kullanarak hem kısa hem de uzun vadeli karar alma süreçlerini desteklemektedir.
2.4.4 Modele Katkısı
WaterNet-LSTM’nin bu yapıdaki kullanımı, su kıtlığı tahminlerinde modelin doğruluğunu artırarak, karar vericilere daha kesin ve uygulanabilir bilgiler sunmaktadır. Modelin geçmiş verilerden öğrenme kapasitesi, gelecekteki eğilimleri tahmin etmede üstün bir performans sağlamaktadır. Ayrıca, WaterNet-LSTM’nin esnek yapısı, yerel veri setleriyle kolayca adapte edilebilmekte ve farklı bölgesel ihtiyaçlara uyarlanabilmektedir. Bu sayede, su kaynaklarının sürdürülebilir yönetimi ve kıtlık risklerine karşı alınacak önlemler daha etkin bir şekilde planlanabilmektedir.
2.4.5 Literatürdeki Kullanım Alanları
WaterNet-LSTM modeli, aşağıdaki uygulama alanlarında başarıyla kullanılmaktadır: Su Kıtlığı Tahmini: Yerel ve bölgesel ölçekte su kıtlığı tahmininde yüksek doğruluk oranları ([20], [21]).
Yeraltı Suyu Akışı: Yeraltı su seviyelerinin uzun vadeli tahminleri için etkili bir araç ([19]). Hidrometeorolojik Analizler: Yağış ve akarsu debisi gibi meteorolojik süreçlerde veri kayıplarını azaltarak daha sağlam analizler yapılmasını sağlar ([18]). Aşağıdaki görsel (Şekil 3), GIS tabanlı analizlerin nasıl kullanıldığını ve WaterNet-LSTM ile entegrasyonunu açıklamaktadır. Harita, alt havzaların sınırlarını, arazi kullanım tiplerini ve yükselti bilgilerini detaylandırarak bu projede mekansal analizlerin karar destek süreçlerine nasıl katkıda bulunduğunu göstermektedir.
Şekil 2.4.5: Harita Bazlı Analiz
2.4.6 Literatürdeki Yaygın Yöntem Türleri ve İncelenmesi
Hidrolojik süreçlerin analizi ve su kaynaklarının yönetimi alanında, literatürde kullanılan yöntemler, geleneksel istatistiksel modellerden modern makine öğrenimi ve derin öğrenme tekniklerine kadar geniş bir yelpazede yer almaktadır. Bu bölümde, yaygın olarak kullanılan yöntem türleri tanıtılmakta ve bu yöntemlerin güçlü ve zayıf yönleri tartışılmaktadır
Su kaynaklarının sürdürülebilir yönetimi ve hidrolojik süreçlerin doğru tahmini, iklim değişikliğinin giderek artan etkileri ve hızla büyüyen nüfus nedeniyle küresel ölçekte kritik bir öneme sahiptir. Bu bağlamda, literatürde hidrolojik süreçlerin analizi ve tahmini için çeşitli yöntemler geliştirilmiştir. Geleneksel istatistiksel yaklaşımlar (örneğin, zaman serisi analizleri) uzun yıllar boyunca bu alanda etkili bir şekilde kullanılmıştır. Ancak, modern teknolojilerin gelişmesiyle birlikte, makine öğrenimi ve derin öğrenme teknikleri, daha yüksek doğruluk oranlarına ve esnek modellere olanak sağlayarak literatürde önemli bir yer edinmiştir.
Bu çalışmada kullanılan WaterNet-LSTM modeli, uzun vadeli bağımlılıkları öğrenme kapasitesini GIS tabanlı mekansal analizlerle birleştirerek literatürdeki bu sınırlamaları gidermeyi amaçlamaktadır. WaterNet-LSTM, su kaynaklarının mekansal ve zamansal özelliklerini bütünleşik bir şekilde modelleyerek, daha kapsamlı ve uygulanabilir tahminler sunmaktadır. Bu bölümde, literatürdeki yaygın yöntemler ve bu çalışmanın bu yöntemlere katkıları ayrıntılı bir şekilde ele alınacaktır.
2.5 Random Forest Regression (RFR)
Random Forest Regression (RFR), birden fazla karar ağacını birleştirerek genelleme kapasitesini artıran bir ensemble öğrenme yöntemidir. Bu yöntemin temel prensibi, veri setinden rastgele örnekler alarak birçok farklı karar ağacı oluşturmaktır. Her bir ağaç, veri setinin farklı bir alt kümesi üzerinde eğitilir ve tahminler yapılırken tüm ağaçların çıktılarının ortalaması alınarak nihai sonuç elde edilir. RFR, özellikle doğrusal olmayan ilişkileri modelleme ve gürültülü veri setlerinde yüksek performans göstermesiyle öne çıkar.
2.5.1 Matematiksel Yapı
Random Forest, temel olarak şu süreçleri içerir:
Bootstrap Örnekleme: Orijinal veri setinden rastgele örnekler alınarak farklı veri alt kümeleri oluşturulur.
Karar Ağaçları Eğitimi: Her bir veri alt kümesi için bağımsız bir karar ağacı eğitilir. Her bir düğümde, belirli sayıda rastgele seçilmiş özelliğe göre en iyi bölme yapılır. Sonuçların Birleştirilmesi: Her bir ağacın yaptığı tahminlerin ortalaması alınarak regresyon problemi için nihai sonuç elde edilir.
RFR, overfitting (aşırı öğrenme) sorununu azaltarak genelleme kapasitesini artıran güçlü bir yöntemdir
2.5.2 Literatürdeki Kullanımı
Hidrolojik süreçlerde RFR, özellikle büyük ve çok boyutlu veri setlerinde kullanılmıştır. Bu yöntemin literatürdeki başlıca kullanım alanları şunlardır:
Yağış ve Akış Tahmini: Karar ağaçlarının güçlü sınıflandırma yetenekleri, hidrolojik döngüdeki ilişkilerin modellenmesinde etkili olmuştur ([25]). Su Kıtlığı Riski Tahmini: RFR, meteorolojik ve sosyoekonomik verileri entegre ederek su kıtlığı risklerini modellemede kullanılmıştır ([26]). Arazi Kullanımının Etkisi: RFR, arazi kullanım tipleri ve su tüketimi arasındaki ilişkileri anlamak için tercih edilmiştir ([27]).
2.5.3 Projemizle İlgisi
Random Forest Regression (RFR), projemizde kullanılan WaterNet-LSTM modeline göre farklı avantajlar sunmasına rağmen, projeye doğrudan uygulanabilir bir çözüm olarak tercih edilmemiştir. Projemizde RFR’nin uygunluğu ve sınırlılıkları şu şekilde özetlenebilir:
- Olumlu Yönler:
- Hidrolojik Süreçlerin Analizi: RFR, doğrusal olmayan ilişkilerin analizinde etkili bir araçtır. Projemizdeki su kaynakları tahminine yönelik veri setlerinde, kısa vadeli bağımlılıkları modelleyebilir.
- Çok Boyutlu Veri Analizi: RFR, birden fazla meteorolojik değişkeni (örneğin yağış, sıcaklık, nem) analiz ederek anlamlı sonuçlar sunabilir.
- Sınırlılıkları:
- Zamansal Bağımlılıkların Modelleme Eksikliği: Projemizin temelinde, uzun vadeli bağımlılıkların modellenmesi yer almaktadır. Ancak RFR, zaman serisi verilerinde bu tür bağımlılıkları öğrenme kapasitesine sahip değildir.
- Mekansal Verilerle Entegrasyon: Projemizdeki GIS tabanlı mekansal analizler, RFR’nin doğrudan desteklemediği bir unsurdur.
Sonuç olarak, RFR, kısa vadeli tahminlerde güçlü bir yöntem olmasına rağmen, zamansal ve mekansal bağımlılıkların modelleme gereksinimi nedeniyle projemizde tercih edilmemiştir. Bunun yerine, WaterNet-LSTM modeli, hem zamansal hem de mekansal analizlerde daha kapsamlı bir çözüm sunmaktadır.
2.6 Hybrid CNN-LSTM Modelleri
Hybrid CNN-LSTM modelleri, Convolutional Neural Networks (CNN) ve Long Short-Term Memory (LSTM) mimarilerinin güçlü yönlerini birleştiren gelişmiş derin öğrenme yöntemleridir. Bu hibrit modeller, hem mekansal (spatial) hem de zamansal (temporal) bağımlılıkları modelleyebilme yetenekleri ile hidrolojik tahminlerde ve su kaynakları yönetiminde yaygın olarak kullanılmaktadır. CNN, girdideki mekansal özellikleri öğrenirken, LSTM, zaman serisi verilerindeki uzun vadeli bağımlılıkları yakalamada etkili bir şekilde çalışır. Bu birleşim, karmaşık hidrolojik süreçlerin daha doğru bir şekilde modellenmesine olanak tanır.
2.6.1 Model Yapısı:
CNN Katmanı: Mekansal özelliklerin öğrenilmesi için kullanılır. Örneğin, hava durumu haritalarındaki desenlerin veya su havzalarının coğrafi özelliklerinin çıkarılmasında etkilidir
CNN, girdideki önemli mekansal ilişkileri filtreler aracılığıyla analiz eder.
LSTM Katmanı: CNN tarafından işlenen mekansal veriler, zaman serisi bağlamında analiz edilmek üzere LSTM katmanına aktarılır. LSTM, geçmişteki zamansal bağımlılıkları öğrenerek gelecekteki tahminler için bu bilgileri kullanır.
Çıkış Katmanı: Zamansal ve mekansal özelliklerin birleşimiyle elde edilen tahmin sonuçlarını sağlar.
2.6.2 Literatürdeki Kullanımı
Hibrit CNN-LSTM modelleri, literatürde su kaynakları yönetimi, hidrolojik tahminler ve iklim değişikliği analizleri gibi alanlarda başarıyla uygulanmıştır:
Hidrolojik Tahminler: CNN, su havzalarındaki coğrafi ve meteorolojik desenleri analiz ederken, LSTM, zaman serisi verilerindeki bağımlılıkları modelleyerek su akışı tahminleri yapmaktadır ([28]).
İklim Değişikliği Etkileri: Bu modeller, farklı bölgelerdeki yağış desenlerini ve buharlaşma oranlarını analiz etmek için kullanılmıştır. Özellikle, zamansal ve mekansal verilerin birlikte işlendiği projelerde doğruluk oranlarını artırmıştır ([29]).
Yağış-Reservuar Modelleri: Yağış miktarları ve rezervuar doluluk oranları gibi parametreleri tahmin ederek bölgesel su yönetiminde karar destek sistemlerine katkı sağlamıştır ([30]).
2.6.3 Projemizle İlgisi
Hybrid CNN-LSTM modelleri, projemizin amacına teknik olarak uyum sağlıyor gibi görünse de, modelin karmaşıklığı ve projedeki spesifik ihtiyaçlara uygunluğu göz önüne alındığında, WaterNet-LSTM modeli tercih edilmiştir. İşte bu hibrit modellerin projemizdeki potansiyel kullanımı ve sınırlamaları:
- Olumlu Yönler:
- Mekansal ve Zamansal Verilerin Analizi: GIS tabanlı mekansal veriler ve zaman serisi verileri birlikte analiz edilerek, daha bütünleşik bir tahmin sistemi oluşturulabilir.
- Karmaşık Süreçlerin Modellenmesi: CNN ve LSTM’nin birleşimi, hidrolojik süreçlerin hem zamansal hem de mekansal bağımlılıklarını modellemede etkili bir yöntemdir.
- Sınırlamaları:
- Hesaplama Maliyeti: Hybrid CNN-LSTM modelleri, yüksek hesaplama gücü ve geniş veri setleri gerektirir. Projemiz, daha optimize bir çözüm sunan WaterNet-LSTM modelini tercih ederek bu zorluktan kaçınmaktadır.
- Veri Seti İhtiyacı: CNN katmanlarının etkili çalışabilmesi için yüksek çözünürlüklü mekansal verilere ihtiyaç vardır. Projemizdeki veri seti, LSTM tabanlı bir yaklaşım için daha uygun yapıdadır.
Sonuç olarak, Hybrid CNN-LSTM modelleri, hem zamansal hem de mekansal analizlerde güçlü bir yöntem sunmasına rağmen, projemizdeki gereklilikler ve optimizasyon ihtiyaçları doğrultusunda tercih edilmemiştir. Bunun yerine, WaterNet-LSTM modeli, zamansal bağımlılıkları modelleme ve mekansal analizlere entegre olma kapasitesiyle daha uygun bir çözüm sunmaktadır.
22 2.7 Extreme Learning Machine (ELM)
Extreme Learning Machine (ELM), yapay sinir ağlarının eğitim süresini optimize etmek ve yüksek doğruluk oranları elde etmek amacıyla geliştirilmiş bir yöntemdir. ELM, gizli katman ağırlıklarını rasgele atayarak ve yalnızca çıkış ağırlıklarını optimize ederek, geleneksel sinir ağlarına kıyasla çok daha hızlı bir şekilde eğitilebilir. Bu yöntem, özellikle hidrolojik süreçlerin tahmini ve su kaynaklarının yönetimi gibi veri yoğun ve karmaşık problemlerde uygulanmaktadır.
2.7.1 Literatürdeki Kullanımı
ELM, literatürde hidrolojik tahminlerde ve su kaynakları yönetiminde sıklıkla kullanılan bir yöntemdir:,
Hidrolojik Süreçlerin Tahmini: ELM, yeraltı su seviyelerinin tahmini ve yağış-akar ilişkilerinin modellenmesi gibi zaman serisi bazlı uygulamalarda başarıyla uygulanmıştır ([31]).
Su Kıtlığı Risk Analizleri: Eğitim süresinin kısalığı ve doğruluk oranının yüksekliği nedeniyle, su kıtlığı risk bölgelerinin hızlı bir şekilde belirlenmesinde etkili bir araç olarak kullanılmıştır ([32]).
Veri Entegrasyonu: ELM, meteorolojik ve hidrolojik verilerin entegrasyonunda kullanılan pratik bir yöntemdir. Özellikle büyük veri setlerinde hızlı analiz yeteneğiyle dikkat çekmiştir ([33]).
2.7.2 Projemizle İlgisi:
Projemizde kullanılan WaterNet-LSTM modeline kıyasla, Extreme Learning Machine (ELM) daha basit bir mimariye sahip olmasına rağmen, özellikle şu yönlerden faydalı olabilirdi:
- Olumlu Yönler:
- Eğitim süresinin hızlı olması, büyük veri setlerinde avantaj sağlar.
- Su kıtlığı risk analizleri gibi kısa vadeli tahminler için uygun bir yöntemdir.
- Sınırlamalar:
- Uzun Vadeli Bağımlılıklar: Projemizde kullanılan zaman serisi verilerinde uzun vadeli bağımlılıkların modellenmesi kritik bir öneme sahiptir. ELM, bu tür bağımlılıkları modelleme kapasitesine sahip değildir.
- Mekansal Veri Entegrasyonu: Projemizde GIS tabanlı mekansal analizler önemli bir rol oynamaktadır. Ancak, ELM mekansal bağımlılıkları modelleme konusunda sınırlı kalmaktadır.
Sonuç olarak, ELM’nin hız ve doğruluk avantajlarına rağmen, projemizde uzun vadeli bağımlılıkların ve mekansal analizlerin gerekliliği nedeniyle WaterNet-LSTM modeli tercih edilmiştir.
2.8 Random Forest Regression (RFR)
Random Forest Regression (RFR), hidrolojik süreçlerin analizi ve tahmininde yaygın olarak kullanılan güçlü bir ensemble (topluluk) öğrenme yöntemidir. Literatürde RFR’nin özellikle üç alanda öne çıktığı görülmektedir. İlk olarak, yağış-akış ilişkilerinin modellenmesinde, RFR doğrusal olmayan karmaşık veri yapılarıyla başa çıkabilme yeteneği sayesinde, akış tahmini ve taşkın analizi gibi uygulamalarda yüksek başarı sağlamıştır [34]. İkinci olarak, arazi kullanımı ile su kaynakları arasındaki ilişkilerin incelenmesinde, bu yöntem, özellikle arazi 23 kullanımındaki değişimlerin su döngüsü üzerindeki etkilerini anlamada etkili bir araç olarak kullanılmıştır [35]. Üçüncü olarak ise, veri gürültüsüne karşı dayanıklılığı, RFR’yi eksik veya gürültülü verilerin yer aldığı hidrolojik çalışmalarda tercih edilen bir yöntem hâline getirmiştir. Bu bağlamda, su kaynaklarının doğru şekilde tahmin edilmesinde RFR’nin yüksek doğruluk oranları sunduğu literatürde sıklıkla vurgulanmaktadır [36].
2.9 Extreme Learning Machine (ELM)
Extreme Learning Machine (ELM), hızlı eğitilebilir yapısı ve yüksek doğruluk oranıyla hidrolojik tahmin alanında öne çıkan bir yöntemdir. En dikkat çekici özelliği, yüksek eğitim hızı sayesinde büyük veri setleri üzerinde düşük hesaplama maliyetiyle kısa sürede etkili tahminler üretebilmesidir [37]. Literatürde, ELM’nin özellikle su kıtlığı risk analizlerinde ve kısa vadeli hidrolojik tahminlerde başarılı sonuçlar verdiği, bu yönüyle alternatif modellere karşı avantaj sağladığı ifade edilmektedir [38]. Ayrıca, mimarisinin basit ama etkili olması — yani gizli katmandaki ağırlıkların rastgele atanması ve yalnızca çıkış ağırlıklarının optimize edilmesi — sayesinde hesaplama yükünü önemli ölçüde azaltmakta ve bu da ELM’yi büyük ölçekli uygulamalarda kullanılabilir kılmaktadır [39].
Tablo 3.3: Literatürdeki modellerin karşılaştırılması
2.10 Data Setler
Bu projede, Türkiye’deki farklı şehirlerde iklim değişikliğine bağlı kuraklık risklerini tahmin edebilmek amacıyla çeşitli meteorolojik parametreler kullanılarak VPD (Vapor Pressure Deficit – Buhar Basıncı Açığı) hesaplanmıştır. Kullanılan veri setleri, güvenilir küresel iklim veri sağlayıcılarından temin edilmiş, ön işleme adımlarından geçirilmiş ve modele uygun hale getirilmiştir.
2.10.1 Meteorolojik Veriler
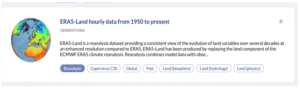
Kaynak: Copernicus Climate Data Store (CDS)
Avrupa Birliği’nin desteklediği Copernicus Climate Change Service (C3S) tarafından sunulmaktadır.
Şekil 2.10.1: Meteorolojik Veriler
Bu çalışmada kullanılan meteorolojik veriler, iklim değişkenlerinin kuraklık üzerindeki etkilerini modelleyebilmek amacıyla seçilmiştir. Veriler, ECMWF (European Centre for Medium-Range Weather Forecasts) tarafından sağlanan ERA5 yeniden analiz ürünlerinden temin edilmiş ve Türkiye’deki 81 ilin coğrafi koordinatlarıyla eşleştirilmiştir. Her bir şehir için zaman serisi halinde elde edilen yıllık ortalama veriler, tahmin modellerine giriş verisi olarak kullanılmıştır. Kullanılan temel iklimsel parametreler ve açıklamaları aşağıda sunulmaktadır:
2.10.1.1 t2m (2 metre hava sıcaklığı)
2 metre yükseklikte ölçülen hava sıcaklığıdır ve biriminin Kelvin (K) olması nedeniyle model öncesinde °C’ye dönüştürülmüştür. Bitki terlemesi, buharlaşma ve VPD hesaplamaları açısından kritik bir değişkendir.
2.10.1.2 d2m (2 metre çiğ noktası sıcaklığı)
Atmosferin nem kapasitesini yansıtan bu veri, nemin doyuma ulaştığı sıcaklık olarak tanımlanır. VPD (Buhar Basıncı Açığı) hesaplamasında t2m ile birlikte kullanılmaktadır.
2.10.1.3 tp (Total precipitation – Toplam yağış)
Yağmur ve kar dahil tüm yağış türlerini içeren yıllık toplam yağış miktarını ifade eder ve birimi metredir (m). Kuraklık analizinde temel göstergelerden biridir.
2.10.1.4 swvl1 (Toprak nemi – Seviye 1)
Toprağın yüzeye en yakın katmanındaki (0–7 cm) hacimsel nem oranını ifade eder. Birimi m³/m³ olup, toprağın su tutma kapasitesi hakkında bilgi verir. Bitki gelişimi ve su ihtiyacıyla doğrudan ilişkilidir.
2.10.1.5 ssrd (Surface solar radiation downwards – Yüzeye gelen kısa dalga radyasyon) Güneş ışınımının yüzeye ulaşan miktarını ifade eder. Birimi joule/metrekare (J/m²) olup, buharlaşma oranlarını ve dolayısıyla bitki su kaybını etkiler.
2.10.2 Türetilmiş Değişken – VPD (Vapor Pressure Deficit, Buhar Basıncı Açığı)
Projede kullanılan hedef değişken, doğrudan herhangi bir veri setinde bulunmayan ancak sıcaklık (t₂m) ve çiğ noktası sıcaklığı (d₂m) verilerinden türetilen Vapor Pressure Deficit (VPD), yani Buhar Basıncı Açığıdır. VPD, özellikle kuraklık tahmini, tarımsal su yönetimi ve atmosferik nem taleplerinin analizinde yaygın olarak kullanılan güçlü bir göstergedir [43]. VPD, havanın taşıyabileceği maksimum nem ile mevcut nem arasındaki farkı temsil eder. Bu fark, atmosferin buharlaştırma potansiyelini yansıtır ve buharlaşma ile bitki terlemesi (transpirasyon) süreçleri üzerinde doğrudan etkili olur. VPD değeri arttıkça, bitkilerin su kaybı da artar; bu da kuraklık stresini artırmakta ve su kaynaklarına olan ihtiyacı yükseltmektedir [44]. Bu nedenle, VPD yalnızca iklimsel etkilerin değil, aynı zamanda ekosistemlerin sürdürülebilirliği açısından da kritik bir parametre olarak değerlendirilir [45]. Sonuç olarak, bu çalışmada VPD, su kıtlığı riskini tahmin etmeye yönelik olarak seçilen hedef değişken olarak kullanılmıştır. Modelleme sürecinde, t₂m ve d₂m verileriyle literatürde yaygın olarak kullanılan hesaplama yöntemi uygulanarak [43] şehir düzeyinde yıllık ortalama VPD değerleri elde edilmiştir. Bu sayede, atmosferik koşulların uzun vadeli değişimlerine duyarlı, güvenilir ve çevresel olarak anlamlı bir tahmin mekanizması geliştirilmiştir.

Şekil 2.10.2: VPD’nin Bilimsel Formülü
2.9. WEB ARAYÜZÜ TEKNOLOJİLERİ
2.9.1. React
React, kullanıcı arayüzleri geliştirmek için kullanılan, bileşen tabanlı ve açık kaynaklı bir JavaScript kütüphanesidir. Facebook tarafından geliştirilmiş olan React, veri değişikliklerine duyarlı yapısıyla SPA (Single Page Application) mimarilerinde yüksek performanslı etkileşimli kullanıcı arayüzleri oluşturulmasına olanak tanır. Sanal DOM yapısı sayesinde sayfa yeniden yüklemesi yapılmadan veri güncellemeleri sağlanabilir.
2.9.2. Vite
Vite, modern ön yüz projeleri için geliştirilmiş yüksek hızlı bir derleme aracıdır. Geliştirme sürecinde hızlı başlatma süresi, modül önbellekleme ve HMR (Hot Module Replacement) desteği sayesinde geliştirme deneyimini önemli ölçüde iyileştirir. React projelerinde Webpack’e göre daha hızlı ve sade bir yapı sunar.
2.9.3. SVG (Scalable Vector Graphics)
SVG, XML tabanlı vektörel grafik biçimidir. Web tabanlı harita uygulamalarında şehir ve bölge bazlı alanları etkileşimli hale getirmek için kullanılabilir. Her bir şehir, SVG içinde ayrı bir path öğesi ile temsil edilir; bu da JavaScript ile olay dinleme ve görselleştirme işlemlerini kolaylaştırır.
2.9.4. JSON ve PapaParse
Veri modeli çıktıları JSON ve CSV formatlarında saklanmıştır. PapaParse, CSV dosyalarını tarayıcı ortamında ayrıştırmak için kullanılan hızlı ve hafif bir JavaScript kütüphanesidir. Bu sayede ham tahmin verileri kolaylıkla okunarak grafik bileşenlerine aktarılmıştır.
2.9.5. Recharts
Recharts, React ile uyumlu bir grafik çizim kütüphanesidir. D3.js temelleri üzerine kurulmuş olmasına rağmen, kullanımı çok daha kolay ve bileşen tabanlıdır. Çizgi grafik, çubuk grafik gibi çeşitli görselleştirme biçimlerini desteklemekte olup bu projede şehir bazlı VPD tahminlerinin görselleştirilmesinde kullanılmıştır.
3.KULLANILAN ARAÇ VE YÖNTEM
Projemizde, WaterNet-LSTM modelinin eğitimi, değerlendirilmesi ve uygulanması için çeşitli yazılım, donanım ve çevrimiçi araçlardan yararlanılmıştır. Bu bölümde kullanılan cihazlar, Google servisleri, uygulama ortamı ve eğitilmiş modeller detaylı bir şekilde açıklanmaktadır.
3.1. Kullanılan Donanım
Model eğitimi ve veri işleme süreçlerinde kullanılan bilgisayar donanımı; Intel Core i7 işlemci, NVIDIA RTX 3060 GPU, en az 16 GB RAM ve 512 GB SSD depolama biriminden oluşmaktadır. Bu donanım, yüksek boyutlu verilerin hızlı işlenmesini ve modelin verimli şekilde eğitilmesini sağlamıştır.
3.2 Kullanılan Yazılım ve Çevrimiçi Araçlar
3.2.1 Google Servisleri
Google Colab, GPU desteği sayesinde büyük ölçekli veri setlerinin işlenmesi ve WaterNet-LSTM modelinin eğitilmesi için kullanılmıştır. Ayrıca, kodların paylaşımı ve ekip içi işbirliği açısından interaktif bir çalışma ortamı sunmuştur. Google Drive ise veri setlerinin depolanması, yönetimi ve eğitim süreci sonunda elde edilen model ağırlıklarının saklanması amacıyla tercih edilmiştir.
3.3 Gerçekleştirme Ortamı
3.3.1 Çalışma Ortamı
Çevrimiçi bir Python geliştirme ortamı olan Google Colab kullanılmıştır. Bu platform, yüksek hesaplama gücü ve GPU erişimi sağlayarak modelin eğitimi için verimli bir çalışma ortamı oluşturmuştur. Eğitim süreçleri ve testler, Jupyter Notebook formatında hazırlanarak proje ekibi ile paylaşılmıştır.
3.3.2 Veri Depolama
Modelin eğitimi sırasında kullanılan büyük veri setleri, Google Drive üzerinden depolanmıştır. Bu yöntem, veri setine kolay erişim ve hızlı işleme imkânı sunmuştur.
3.4. Eğitilecek Modeller
WaterNet-LSTM Modeli:
Eğitim Verileri: Yerel meteorolojik ve hidrolojik veriler (örneğin, yağış, sıcaklık ve su akışı). Eğitim Süresi: Ortalama 14-16 saatlik GPU tabanlı eğitim süreci.
Sonuç: Eğitilmiş model, gelecekteki su kaynakları tahmini ve su kıtlığı risk analizlerinde kullanılabilecek bir araç olarak optimize edilmiştir.
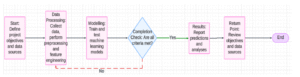
3.5 Projenin Akış Diyagramı
Şekil 3.5: Projenin Akış Diyagramı
Bu proje akış diyagramı, su kaynaklarının yönetimi için izlenecek süreci sistematik bir şekilde göstermektedir. Süreç, proje hedeflerinin ve veri kaynaklarının tanımlanmasıyla başlar. Ardından, toplanan verilerin ön işleme ve özellik mühendisliği adımları gerçekleştirilir. Eğitim ve test aşamalarında, makine öğrenimi modelleri (özellikle WaterNet-LSTM) optimize edilir ve değerlendirilir. Modelin belirlenen kriterleri karşılamaması durumunda süreç geri döner ve gerekli düzeltmeler yapılır. Tüm kriterler sağlandığında, tahminler ve analizler raporlanır, sonuçlar değerlendirilerek proje tamamlanır. Bu yapı, çalışmanın düzenli ve verimli bir şekilde ilerlemesini sağlar.
3.6 Web Tabanlı Görselleştirme Sistemi
Projenin model çıktılarının kullanıcıya şehir bazında sunulabilmesi için bir web tabanlı arayüz geliştirilmiştir. Bu sistem, Türkiye haritası üzerinden şehir seçimi yaparak, seçilen şehir için modelin tahmin ettiği 5 yıllık VPD (Vapor Pressure Deficit) değerlerini grafiksel olarak göstermektedir.
Uygulama, JavaScript tabanlı modern bir kütüphane olan React kullanılarak geliştirilmiştir. Şehir isimleri SVG harita üzerine entegre edilmiş, kullanıcılar harita üzerinde bir şehre tıkladığında ilgili veriler JSON/CSV formatında okunarak, etkileşimli grafik bileşenleri üzerinden görselleştirilmiştir.
Her şehir için tahmini 5 yıllık VPD değeri çizgi grafikle görselleştirilmiş, 2030 yılına ait VPD değeri kPa cinsinden sayısal olarak sunulmuş ve bu değere karşılık gelen kuraklık seviyesi (Low(Düşük), Moderate(Normal), High(Yüksek)) renk kodlu bir etiketle belirtilmiştir. Bu görsel sistem, modelin bilimsel çıktılarının genel kullanıcıya sade ve anlaşılır biçimde aktarılmasını sağlayarak sürdürülebilir su yönetimine yönelik karar alma süreçlerine katkı sunmayı hedeflemektedir.
3.7 Kullanılan Kütüphaneler:
Bu çalışmada, VPD tahmini üzerine kurulu makine öğrenimi modellerinin oluşturulması, eğitilmesi, değerlendirilmesi ve görselleştirilmesi süreçlerinde Python programlama dili kullanılmıştır. Proje süresince çeşitli açık kaynaklı kütüphanelerden faydalanılmış, veri bilimi odaklı bütünsel bir analiz altyapısı oluşturulmuştur. Aşağıda, proje kapsamında kullanılan başlıca kütüphaneler ve kullanım amaçları açıklanmıştır:
3.7.1. NumPy
NumPy kütüphanesi, sayısal işlemler ve çok boyutlu diziler üzerinde yüksek performanslı hesaplamalar gerçekleştirmek amacıyla kullanılmıştır. Projede, model girdisi olan X ve çıktısı olan Y dizilerinin oluşturulması, matris işlemleri, diziler arası dönüşümler ve veri şekillerinin kontrolü gibi işlemler için temel araç olarak görev yapmıştır.
3.7.2 Pandas
Pandas kütüphanesi, tabular veri yapıları üzerinde okuma, düzenleme, analiz ve veri manipülasyonu işlemleri için kullanılmıştır. Proje kapsamında; CSV dosyalarından veri yükleme, eksik veri analizi, şehir bazlı filtreleme, yıllık ortalamaların hesaplanması ve OneHotEncoder gibi dönüştürme işlemlerinin sonuçlarının DataFrame yapısına entegre edilmesi gibi görevlerde etkin şekilde kullanılmıştır.
3.7.3 Matplotlib & Seaborn
Matplotlib ve Seaborn kütüphaneleri, veri görselleştirmesi ve istatistiksel analiz sonuçlarının anlaşılır şekilde sunulması amacıyla kullanılmıştır. Projede; eksik veri oranlarının gösterimi, aykırı değer analizinde boxplot ve histogram çizimi, değişkenler arası korelasyon matrislerinin ısı haritası şeklinde sunulması ve model tahminlerinin gerçek verilerle karşılaştırıldığı grafiklerin oluşturulması gibi görsel analizlerde aktif rol oynamıştır.
3.7.4 Scikit-learn
Scikit-learn kütüphanesi, makine öğrenimi öncesi veri işleme, temel modellerin uygulanması ve model başarımının değerlendirilmesi amacıyla kullanılmıştır. Projede; girdi değişkenlerinin normalize edilmesi için MinMaxScaler, şehir gibi kategorik değişkenlerin sayısal formata dönüştürülmesi için OneHotEncoder, veri setinin eğitim ve test kümelerine ayrılması için train_test_split fonksiyonları kullanılmıştır. Ayrıca, tahmin performansını değerlendirmek üzere MAE, RMSE ve SMAPE gibi metriklerin hesaplandığı özel fonksiyonlar bu kütüphane ile birlikte geliştirilmiştir.
3.7.5 TensorFlow & Keras
Derin öğrenme temelli modellerin (GRU ve WaterNet-LSTM) oluşturulması, eğitilmesi ve değerlendirilmesi amacıyla TensorFlow ve Keras kütüphaneleri kullanılmıştır. Model mimarisi GRU, LSTM, Conv1D, Dropout, RepeatVector, Add ve TimeDistributed gibi katmanlarla yapılandırılmıştır. Eğitim sürecinde fit(), EarlyStopping, ModelCheckpoint ve ReduceLROnPlateau fonksiyonları uygulanarak eğitim performansı optimize edilmiştir. Modelin değerlendirilmesi evaluate() ve predict() fonksiyonlarıyla yapılmış, ayrıca KerasTuner ile WaterNet mimarisi için hiperparametre optimizasyonu gerçekleştirilmiştir.
3.7.6 Keras Tuner
Keras Tuner, derin öğrenme modellerinde hiperparametre optimizasyonu yapmak amacıyla kullanılmıştır. WaterNet mimarisi kapsamında; conv_blocks, dropout, learning_rate ve units gibi parametrelerin çeşitli kombinasyonları sistematik olarak test edilmiş, böylece en yüksek performansa sahip model yapılandırması belirlenmiştir.
3.7.7 xarray ve netCDF4:
xarray ve netCDF4 kütüphaneleri, veri hazırlık aşamasında ERA5 iklim verilerinin işlendiği GRIB ve NetCDF formatlı dosyaların okunması için kullanılmıştır. Bu araçlar sayesinde t2m, d2m, tp, swvl1 ve ssrd gibi değişkenler; enlem (latitude), boylam (longitude) ve zaman (time) boyutlarına göre analiz edilmiştir. Ayrıca Türkiye sınırları dışındaki karasal veriler filtrelenerek veri setinden çıkarılmış ve yalnızca ilgili bölgelere ait bilgiler işlenmiştir.
4.SİSTEMİN GERÇEKLENMESİ
4.1. Veri Hazırlama ve Girdi/Çıktı Yapısı
Bu çalışmada kullanılan veri seti, Copernicus ERA5 Reanalysis verileri temel alınarak oluşturulmuştur. ERA5, Avrupa Orta Vadeli Hava Tahminleri Merkezi (ECMWF) tarafından sağlanan küresel iklim verilerini içeren bir veri kümesidir. Türkiye sınırları içerisindeki 81 şehir için 2010–2024 yılları arasını kapsayan yıllık ortalama meteorolojik parametreler, belirli bir grid yapısına uygun olarak GRIB dosyalarından çıkarılmış ve şehir bazlı olarak işlenmiştir.
Kullanılan veri kaynağı boyut, özellik ve değişkenleri aşağıda gösterilmiştir:
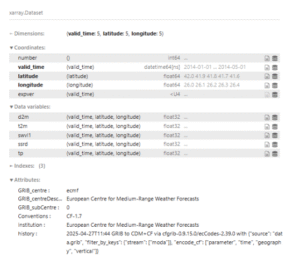
Şekil 4.1: Veri Kaynağı ve Boyutları
4.2 Eksik Verilerin Analizi ve Temizlenmesi
Toplanan ERA5 verileri üzerinde yapılan ilk analizlerde, her bir değişken için %16.78 oranında eksik (NaN) değer bulunduğu tespit edilmiştir. Eksiklik durumu, aşağıdaki meteorolojik parametrelerde aynı düzeyde gözlenmiştir:

Eksik değerlerin mekânsal dağılımı analiz edildiğinde, bu verilerin büyük çoğunluğunun Türkiye’nin kara sınırları dışında kalan grid hücrelerine ait olduğu tespit edilmiştir. Bu durum, ERA5 veri kümesinin sabit grid sistemine dayalı olmasından kaynaklanmaktadır. Özellikle Akdeniz, Ege ve Karadeniz açıklarında kalan noktalarda sistematik boşluklar gözlenmiştir.
Eksik veri maskesi, tüm değişkenler üzerinden aşağıdaki şekilde analiz edilmiş ve görselleştirilmiştir:
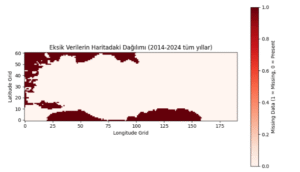
Şekil 4.2: Eksik Verilerin Haritadaki Dağılımı
Eksik veri haritası oluşturularak eksik değerlerin coğrafi konumu belirlenmiştir. Koordinatlarla elde edilen haritada, kara sınırlarının dışında kalan bölgelerde yoğunluk gözlenmiştir.
Sonuç olarak, yalnızca Türkiye sınırları içinde yer alan kara grid hücreleri filtrelenmiş ve bu alanlardaki eksik değerler tamamen veri kümesinden çıkartılmıştır. Böylece modelleme sürecinde eksik veri bulunmayan, homojen ve coğrafi olarak sınırlı bir örneklem üzerinde çalışılmıştır.
4.3 Aykırı Değer (Outlier) Analizi
Modelin güvenilir tahminler üretebilmesi için veri setinde yer alan meteorolojik değişkenlerin dağılımı ve uç değerleri detaylı şekilde incelenmiştir. Bu amaçla her bir değişken için hem boxplot (kutu grafiği) hem de histogram kullanılarak aykırı değer analizleri gerçekleştirilmiştir. Elde edilen bulgular aşağıda özetlenmiştir:
4.3.1. Temperature 2m (T2M)
Ortalama sıcaklık değerleri genellikle 280–295 K (yaklaşık 7–22 °C) aralığında yoğunlaşmakta olup, dağılım simetrik ve dengeli bir yapı sergilemektedir. Verilerde ciddi bir sapma gözlemlenmemiştir. Aykırı değerler ise oldukça az sayıda olup, genellikle yüksek rakım gibi coğrafi olarak uç bölgelerde ortaya çıkmaktadır. Bu değerler, doğanın doğal varyansı kapsamında değerlendirilmiş ve veri setinden dışlanmamıştır.
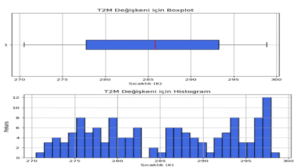
Şekil 4.3.1: T2M Outlier Analizi
4.3.2. Dewpoint 2m (D2M)
D2M verileri, çan eğrisi şeklinde simetrik bir dağılım sergilemektedir. Boxplot analizi, 260 K altı ve 290 K üzerindeki değerlerin aykırı sınıfa girdiğini göstermektedir. Histogram sonuçlarına göre, D2M değerleri çoğunlukla 275–285 K aralığında yoğunlaşmaktadır. Aykırı değerler sınırlı sayıda olup, genel olarak normal iklim varyasyonlarının doğal bir sonucu olarak kabul edilmiştir.
4.3.3. Total Precipitation (TP)
Yağış (TP) verileri, sağa çarpık (pozitif skew) bir dağılım göstermektedir. Histogram analizinde değerlerin büyük çoğunluğunun 0–0.003 m aralığında yoğunlaştığı gözlemlenmiştir. Boxplot incelemesinde ise yüksek uç değerler sıkça görülmüş, bu durum yağışın Türkiye genelindeki bölgesel eşitsizliğinden (örneğin Karadeniz ve İç Anadolu farkı) kaynaklanmaktadır. Bu nedenle, TP değişkenindeki uç değerler veri setinden çıkarılmamış, modelin bu doğal varyasyonu öğrenebilmesi amaçlanmıştır.
4.3.4 Soil Moisture (SWVL1)
SWVL1 değişkeni için dağılım oldukça parçalı olup, histogram analizinde çift modlu (bimodal) bir yapı gözlemlenmiştir. Bu durum, Türkiye’nin topografik ve iklimsel çeşitliliğini yansıtmaktadır. Boxplot incelemesinde 0.55 m³/m³ üzerindeki değerler uç değer olarak tanımlansa da, bu değerler doğal toprağın su tutma kapasitesinin bir sonucu olarak kabul edilmiştir. Bu nedenle, veri setinde herhangi bir dışlama yapılmadan veri bütünlüğü korunmuştur.
4.3.5 Surface Solar Radiation (SSRD)
SSRD (Surface Solar Radiation) değişkeni yaklaşık 0.5 × 10⁷ ile 3.0 × 10⁷ J/m² arasında geniş bir aralıkta dağılmıştır. Histogram incelemesinde çok merkezli (multimodal) bir dağılım yapısı gözlemlenmiş, bu da Türkiye genelindeki farklı iklim ve coğrafi koşulları yansıtmaktadır. Boxplot analizinde aykırı değerlere nadiren rastlanmıştır. SSRD verisindeki bu varyasyon, şehirlerin enlemlerine ve coğrafi eğimlerine bağlı doğal bir farklılık olarak değerlendirilmiş ve dışlanmamıştır.
4.3.6 Aykırı Değer ve Eksik Değer Genel Değerlendirmesi
Genel değerlendirme sonucunda, tüm değişkenlerde yapılan istatistiksel analizler, aykırı değerlerin büyük ölçüde veri hatasından değil; Türkiye’nin coğrafi ve iklimsel çeşitliliğinden kaynaklandığını ortaya koymuştur. Ekstrem değerlerin model performansına olumsuz etkisi olduğuna dair belirgin bir istatistiksel bulguya rastlanmamıştır. Bu nedenle, herhangi bir aykırı değer çıkarımı yapılmamış, veri seti olduğu gibi korunmuş ve sadece normalizasyon işlemleri uygulanarak değişkenlerin etkisi dengelenmiştir.
4.4 Özellik Seçimi ve Hedef Değişkenin Türetilmesi
Bu çalışmada, gelecekteki kuraklık eğilimlerini tahmin edebilmek amacıyla, şehir bazlı yıllık meteorolojik verilerden anlamlı bir hedef değişken türetilmesi hedeflenmiştir. Bu kapsamda, literatürde yaygın olarak kullanılan ve kuraklıkla doğrudan ilişkili bir parametre olan Buhar Basıncı Açığı (VPD – Vapor Pressure Deficit), veri kümesinde yer alan temel sıcaklık değişkenlerinden hesaplanarak oluşturulmuştur.
4.4.2 Korelasyon Analizi ile Girdi Değişkenlerinin Belirlenmesi
Modelin eğitileceği bağımsız değişkenlerin belirlenmesinde hem fiziksel anlamlılık hem de değişkenler arası istatistiksel korelasyonlar dikkate alınmıştır. Tüm sayısal değişkenler arasında oluşturulan korelasyon matrisi sonucunda bazı önemli ilişkiler tespit edilmiştir. Özellikle 2 metre sıcaklık (t2m) ile çiğ noktası sıcaklığı (d2m) arasında güçlü bir pozitif korelasyon gözlenmiştir (r = 0.84); bu ilişki, bu iki değişkenin VPD (Vapor Pressure Deficit) hesaplamasında birlikte kullanıldığını da desteklemektedir. Ayrıca t2m ile yüzey güneş radyasyonu (ssrd) arasında anlamlı pozitif korelasyon (r = 0.72), t2m ile toprak nemi (swvl1) arasında belirgin negatif korelasyon (r = -0.70) ve toplam yağış (tp) ile swvl1 arasında orta düzey pozitif ilişki (r = 0.66) saptanmıştır. Bu analizler doğrultusunda, t2m ve d2m değişkenleri VPD’nin doğrudan hesaplanması için temel girdiler olarak modellemeye dahil edilmiştir. Diğer değişkenler (tp, swvl1, ssrd) ise VPD’yi etkileyebilecek ikincil faktörler olarak değerlendirilerek modele yardımcı öznitelikler şeklinde entegre edilmiştir.
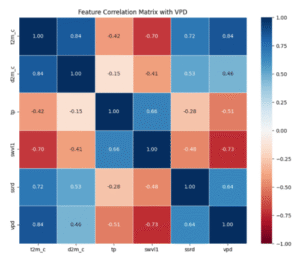
Şekil 4.4.2: Girdi değişkenleri arasındaki Pearson korelasyonlarını gösteren ısı haritası.
4.4.3 Sonuç Olarak Seçilen Girdi Değişkenleri
Modelin son halindeki giriş değişkenleri, hem iklimsel hem de coğrafi faktörleri temsil eden parametrelerden oluşmaktadır. Kullanılan girdiler şunlardır: toplam yıllık yağış (tp, m), yüzey katman toprak nem oranı (swvl1, m³/m³), yüzeye gelen güneş ışınımı (ssrd, J/m²), buhar basıncı açığı (vpd, kPa) ve Türkiye’deki 81 ili temsil eden one-hot encoded şehir bilgisi (city_normalized). t2m ve d2m verileri, yalnızca VPD değişkeninin hesaplanmasında kullanılmış olup doğrudan model girdisi olarak yer almamıştır. Ancak türetilmiş olan VPD değişkeni, geçmiş yıllardaki kuraklık eğilimlerini öğrenebilmesi için doğrudan modele giriş olarak eklenmiştir. Tüm veriler, şehir düzeyinde yıllık ortalamalara çevrilmiş ve bu doğrultuda şehir-zaman temelli giriş matrisleri oluşturularak model eğitimi için kullanıma hazır hale getirilmiştir.
4.5 Girdi ve Çıktı Yapısının Belirlenmesi, Ölçekleme ve Zaman Penceresi Oluşturma
Model eğitimi öncesinde tüm veriler aşağıdaki ön işleme adımlarından geçirilmiştir
4.5.1 Özellik Ölçekleme
Model girişindeki tüm sayısal değişkenler (t2m, d2m, tp, swvl1, ssrd) MinMaxScaler kullanılarak 0 ile 1 arasına normalize edilmiştir. Bu işlem, modelin her özelliği benzer büyüklüklerde işleyebilmesini sağlamak ve eğitim sürecinde dengesiz öğrenme riskini azaltmak amacıyla yapılmıştır.
4.5.2 Zaman Serisi Pencereleme (Sliding Window)
Her şehir için, son 10 yılın verileri bir giriş dizisi olarak tanımlanmış ve takip eden 5 yılın VPD değerleri hedef (çıktı) olarak belirlenmiştir. Bu yapı sayesinde model, geçmiş 10 yıla bakarak gelecek 5 yılın kuraklık riskini tahmin etmeyi öğrenmiştir.
4.5.3 Girdi ve Çıktı Boyutları:
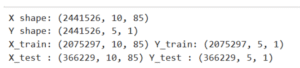
Şekil 4.5.3: Girdi ve Çıktı Boyutları
Buradaki 85 özellik, 5 adet meteorolojik parametre ve 81 şehir bilgisinin (one-hot encoded) birleşiminden oluşmaktadır.
Veri kümesi eğitim ve test olarak %85-%15 oranında ayrılmıştır. Model sadece eğitim verileri üzerinde öğrenmiş, başarım değerlendirmesi ise ayrılan test verileriyle yapılmıştır.
4.6 Model Eğitimi
Bu çalışmada, Türkiye’nin 81 ili için 5 yıllık bir VPD (Vapor Pressure Deficit) tahmini gerçekleştirmek amacıyla farklı derin öğrenme tabanlı zaman serisi modelleme yöntemleri uygulanmıştır. Kullanılan modeller arasında GRU (Gated Recurrent Unit) temelli iki farklı yapı (basitleştirilmiş ve gelişmiş sürüm) ile WaterNet-LSTM tabanlı iki yapı (bir temel model, bir hiperparametre ayarlı model) yer almıştır.
4.6.1 GRU Modelleri
Proje kapsamında VPD tahmini için Gated Recurrent Unit (GRU) temelli iki farklı sekans-sekans mimarisi uygulanmıştır. Bu modellerden ilki düşük parametreli ve hızlı eğitilebilen bir yapı olan Fast GRU, ikincisi ise daha derin ve düzenlemeli katmanlardan oluşan Enhanced GRU mimarisidir. Her iki model de encoder–decoder yapısında tasarlanmış ve aynı ön işleme prosedürleri uygulanarak eğitilmiştir.
4.6.1.1 Veri Yapısı ve Ön İşleme
Her iki modelin eğitiminde kullanılan veri biçimi aynıdır:
Girdi verisi (X): Her örnek 10 yıllık zaman penceresi içinde 85 özelliği temsil eden bir tensör olup, şekli (örnek sayısı, 10, 85) biçimindedir. Özellikler arasında 4 meteorolojik parametre (swvl1, ssrd, tp, vpd) ile 81 ilin one-hot kodlanmış temsili yer almaktadır.
Çıktı verisi (Y): Her girdiye karşılık gelen 5 yıllık VPD tahmin değerlerini içermekte olup, şekli (örnek sayısı, 5, 1) biçimindedir.
Ön işleme aşamasında, tüm özellikler MinMaxScaler kullanılarak [0, 1] aralığına ölçeklendirilmiştir. Eğitimden sonra model çıktıları tekrar özgün birimlerine (kPa) dönüştürülerek değerlendirme metrikleri hesaplanmıştır.
4.6.2 Fast GRU Modeli
Fast GRU modeli, düşük hesaplama maliyetiyle kısa sürede tahmin yapabilmesi amacıyla geliştirilmiştir. Temel özellikleri şunlardır:
Encoder: TimeDistributed(Dense) ile girdi daraltılır, ardından tek bir Bidirectional GRU (48 birim) katmanı uygulanır.
Ara katmanlar: BatchNormalization, Dropout ve Dense katmanları ile öğrenme süreci stabilize edilmiştir.
Decoder: RepeatVector sonrası tek bir GRU (32 birim) ile 5 yıllık tahmin dizisi üretilir.
Çıkış: TimeDistributed(Dense) katmanları ile her yıl için 1 değer tahmin edilir.
Model 11 epoch’ta eğitilmiş ve en düşük doğrulama kaybı 0.0014 olarak kaydedilmiştir.
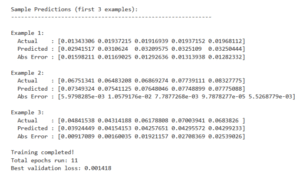
Şekil 4.6.2: Fast GRU Modeli Test Sonuçları
Test Performansı:
- Toplam MAE: 0.0293
- Toplam RMSE: 0.0513 36
4.6.3 Enhanced GRU Modeli
Enhanced GRU modeli, Fast GRU’nun aksine çok katmanlı ve düzenlemeli bir yapıya sahiptir. Karmaşık örüntüleri daha iyi öğrenebilmesi için aşağıdaki yapı uygulanmıştır:
Encoder: Üç adet GRU katmanı: İlk ikisi return_sequences=True, sonuncusu return_sequences=False
Bidirectional GRU (128 birim) + GRU (96) + GRU (64)
Decoder: RepeatVector ardından iki GRU (64 ve 48 birim) uygulanmıştır.
Düzenleyiciler: Her aşamada BatchNormalization, Dropout ve l1_l2 regularization kullanılmıştır.
Çıkış: TimeDistributed(Dense) dizileri ile çıktı üretilmiştir.
Model, 31 epoch süresince eğitilmiş ve en iyi doğrulama kaybı 0.0027 olarak ölçülmüştür.
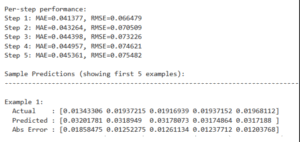
Şekil 4.6.3: Enhanced GRU Performance
4.6.3.1 Enhanced GRU Test Performansı (Ham VPD Değeri ile):
Toplam MAE: 0.1298
Toplam RMSE: 0.2388
SMAPE (ortalama): 34.35%
Bu veriler, Fast GRU’nun düşük hata oranları ile dikkat çekici bir performans sergilediğini, buna karşılık Enhanced GRU modelinin daha derin yapısıyla bazı örneklerde daha stabil tahmin sağladığını göstermektedir. Her iki modelin sonuçları, tartışma bölümünde ayrıntılı biçimde analiz edilmiştir.
4.7 WaterNet-LSTM Modelleri
GRU tabanlı modellerin ardından, literatürde özellikle su kaynakları üzerine yapılan tahmin problemleri için önerilen bir yaklaşım olan WaterNet-LSTM mimarisi değerlendirilmiştir. Bu yapı, konvolüsyonel bloklar ile zaman serisinden yüksek seviyeli özellik çıkarımı yaptıktan sonra encoder–decoder yapısı üzerinden çok adımlı tahmin üretmektedir. Model, VPD tahmin performansını değerlendirmek amacıyla iki farklı senaryoda uygulanmıştır: Baseline (öntanımlı yapı) ve Tuned (hiperparametre optimizasyonu yapılmış yapı).
4.7.1 Veri Yapısı ve Ön İşleme
WaterNet modelleri de GRU modelleri ile aynı veri yapısını kullanmaktadır:
Girdi verisi (X): (örnek sayısı, 10, 85) boyutunda olup, son 10 yıllık veriler ile 4 meteorolojik parametre ve 81 ilin one-hot temsili içerir.
Çıktı verisi (Y): (örnek sayısı, 5, 1) şeklinde olup, 5 yıllık VPD tahminlerini içerir.
Girdi değerleri, eğitim öncesinde MinMaxScaler ile [0, 1] aralığına normalize edilmiş ve model çıktılarına uygulanan ters dönüşüm ile gerçek kPa biriminde değerlendirme yapılmıştır.
4.7.2 WaterNet-LSTM (Baseline)
Baseline model, varsayılan mimari ayarlarıyla aşağıdaki gibi yapılandırılmıştır:
Konvolüsyonel Blok: 2 adet Conv1D (64 filtre, causal padding) katmanı ve BatchNormalization katmanları ile zaman serisi özelliklerinden anlamlı örüntüler çıkarılmıştır.
Encoder: LSTM (128 birim) + Dropout (0.2)
Decoder: RepeatVector (5) sonrası LSTM (64 birim) uygulanarak çok adımlı çıktı oluşturulmuştur.
Skip Connection: Konvolüsyonel bloktan gelen çıktılar, Dense ile 5 zaman adımına yayılmış ve ana akışla toplanarak son TimeDistributed(Dense) katmanına iletilmiştir.
Model, 10 epoch boyunca eğitilmiş ve doğrulama verisi üzerinden erken durdurma uygulanmıştır.
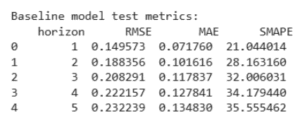
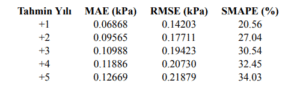
Şekil 4.7.2: Test Metrics
4.7.2.1 Test Performansı (WaterNet Baseline):
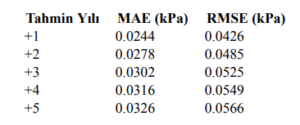
WaterNet-LSTM (Baseline) modelinin test veri seti üzerindeki 5 yıllık tahmin performansını ortaya koymaktadır. Performans metrikleri incelendiğinde, modelin doğruluk oranının tahmin yılı ilerledikçe kademeli olarak düştüğü gözlemlenmektedir. İlk yıl için RMSE değeri 0.1495 kPa, MAE değeri 0.0712 kPa ve SMAPE oranı %21.04 olarak oldukça başarılı bir tahmin performansı sergilemiştir. Ancak, zaman ufku ilerledikçe hata oranlarında artış yaşanmıştır; 5. yıl tahmini için RMSE değeri 0.2322 kPa’ya, MAE değeri 0.1348 kPa’ya ve SMAPE oranı %35.55’e yükselmiştir.
Bu artış,modelin gelecekteki belirsizlikleri öngörme konusundaki sınırlarını yansıtmaktadır. Yine de 5 yıllık bir tahmin için %35’in altındaki SMAPE değerleri, modelin özellikle kısa ve orta vadeli projeksiyonlarda güvenilir çıktılar üretebildiğini göstermektedir. Ayrıca, SMAPE oranının zamanla artmasına rağmen makul düzeyde kalması, modelin öğrenme kapasitesinin dengeli olduğunu ve overfitting eğiliminden kaçındığını da göstermektedir.
4.7.3 WaterNet-LSTM (Tuned)
Tuned versiyon, Keras Tuner ile hiperparametre araması sonucu elde edilen en uygun mimari ve optimizasyon ayarlarıyla yeniden eğitilmiştir. Aşağıdaki önemli değişiklikler yapılmıştır:
Konvolüsyonel Bloklar: 3 blok (her biri 64 filtreli)
Encoder LSTM birimi: 256
Decoder LSTM birimi: 32
Dropout oranları: Encoder için 0.4, decoder için 0.3
Öğrenme oranı: 3.09 × 10⁻⁴
Batch boyutu: 256
Model 100 epoch boyunca erken durdurma ile eğitilmiş ve en düşük doğrulama hatası sağlandığında sonlandırılmıştır.

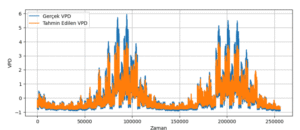
Şekil 4.7.3: Gerçek VPD vs Tahmin Edilen
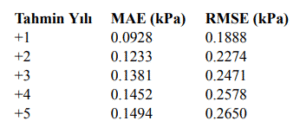
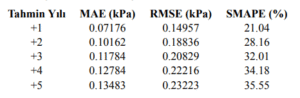
4.7.3.1 Test Performansı (WaterNet Tuned):
Sonuçlar, hiperparametre optimizasyonu ile yapılan düzenlemelerin model performansını her bir zaman adımında anlamlı ölçüde artırdığını göstermektedir. Ayrıca, WaterNet modelleri uzun dönemli VPD tahminlerinde GRU mimarilerine göre daha istikrarlı tahminler üretme eğilimindedir. Bu gözlem, sonraki bölümde detaylı olarak tartışılmıştır.
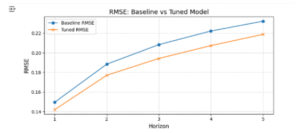
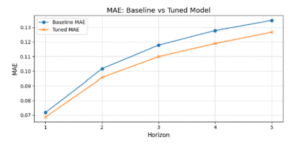
Şekil 4.7.3.1: Test Performansı Tuned vs Baseline
4.7.4 Karşılaştırmalı Model Performansları
Bu çalışmada eğitilen dört farklı modelin performansı, test veri kümesi üzerinde hesaplanan metriklerle karşılaştırmalı olarak değerlendirilmiştir. Kullanılan değerlendirme ölçütleri arasında Ortalama Mutlak Hata (MAE), Kök Ortalama Kare Hata (RMSE) ve Simetrik Ortalama Yüzde Hata (SMAPE) yer almaktadır. Her modelin beş tahmin adımı (5 yıllık gelecek) için ortalama test performansı aşağıdaki tabloda sunulmuştur:
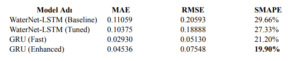
Tablo 5.3 – Modellerin Ortalama Test Performans Karşılaştırması
Tablo 5.3’teki sonuçlara göre, en iyi performansı gösteren GRU (Fast) modeli yaklaşık %97 doğruluk (MAE ≈ 0.0293) sağlamıştır. Bu değer, tahmin edilen VPD’nin gerçek değerden ortalama yalnızca 0.0293 kPa saptığını göstermektedir. En düşük yüzde hata oranını veren GRU (Enhanced) modeli ise %80’in üzerinde bir genel doğruluk ve sadece %19.90 SMAPE değeriyle öne çıkmıştır. Bu da modelin VPD tahminlerinde oldukça başarılı ve güvenilir çıktılar ürettiğini göstermektedir.
WaterNet-LSTM modelleri ise karmaşık konvolüsyonel ve LSTM katmanlarına rağmen daha yüksek hata oranları üretmiştir. Baseline sürümdeki düşük performans, parametrik esneklik eksikliğinden kaynaklanırken; Tuned versiyonda yapılan hiperparametre optimizasyonuna rağmen modelin genellenebilirliği sınırlı kalmıştır. Bu durum, WaterNet mimarisinin yüksek model karmaşıklığının mevcut veri setinde aşırı öğrenme (overfitting) eğilimi göstermesine bağlanabilir.
Sonuç olarak, GRU mimarisi hem yapısal sadelik hem de yüksek doğruluk düzeyi sayesinde proje kapsamında kullanılacak ana model olarak seçilmiştir. Özellikle Fast GRU modeli, eğitim süresindeki verimliliği ve hata oranlarındaki düşüklüğüyle uygulamaya en uygun alternatif olarak değerlendirilmiştir.
Bu doğruluk oranları özellikle iklimsel tahminlerde değerlendirildiğinde anlamlıdır. Zira iklim verileri doğası gereği hem gürültülü hem de uzun dönemli eğilimlere dayalıdır. Bu bağlamda, %80’in üzerinde doğruluk sağlayan GRU modelleri, kısa ve orta vadeli projeksiyonlar açısından güvenilir öngörüler üretmiştir. Ayrıca VPD gibi sıcaklık ve nem dengesine bağlı bir göstergede, mutlak kPa sapmaların sınırlı kalması, modelin pratik anlamda başarılı olduğunu göstermektedir. Özellikle SMAPE oranının %20’nin altında kalması, modelin oransal hata açısından yüksek duyarlılıkla çalıştığını ve ekstrem tahmin hatalarının büyük sapmalara neden olmadığını ortaya koymaktadır.
4.7.5 Şehir Bazlı Model Çıktıları (2029 Tahminleri)
Sınıflandırılmış kuraklık seviyesi toplam şehir bazlı aşağıda gösterilmiştir.
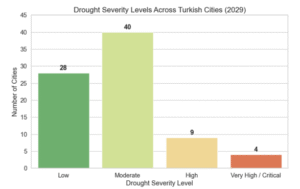
Şekil 4.7.5 : Şehir Bazlı Model Çıktıları
2029 yılı için modellenen VPD tahminlerine göre Türkiye’deki şehirlerin sınıflandırılmış kuraklık seviyeleri sunulmuştur. Sonuçlara göre, 40 şehir “Orta (Moderate)” düzeyde kuraklık riski taşırken, 28 şehir “Düşük (Low)” risk grubunda yer almaktadır. Buna karşılık, 9 şehir “Yüksek (High)” ve 4 şehir ise “Çok Yüksek / Kritik (Very High / Critical)” risk grubuna girmektedir. Bu dağılım, modelin büyük bir kısmı için sürdürülebilir seviyelerde risk öngördüğünü gösterse de, belirli bölgelerde ciddi kuraklık tehditlerinin olduğunu ortaya gösterir.
4.7.5.1 En yüksek kuraklığa sahip 10 şehir
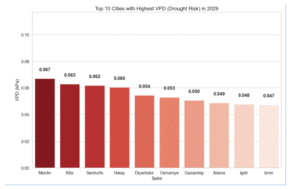
Şekil 4.7.5.1: En yüksek kuraklığa sahip 10 şehir
Bu grafikte, modelin 2029 yılı için tahmin ettiği en yüksek VPD değerlerine sahip ilk 10 şehir sunulmaktadır. Mardin, Kilis, Şanlıurfa, Hatay ve Diyarbakır gibi şehirler, sırasıyla 0.067, 0.063, 0.062, 0.060 ve 0.054 kPa ile listenin başında yer almakta ve ciddi düzeyde kuraklık riski taşımaktadır. Bu şehirlerin ortak özelliği, yarı kurak ve sıcak iklim kuşağında yer almalarıdır. Özellikle Güneydoğu Anadolu Bölgesi’ne ait bu iller, su stresi açısından öncelikli müdahale ve izleme gerektiren bölgeler olarak değerlendirilebilir.
4.7.5.2 En düşük kuraklığa sahip 10 şehir
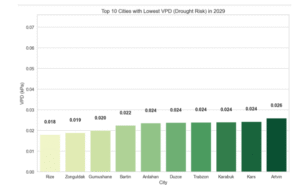
Şekil 4.7.5.2: En düşük kuraklığa sahip 10 şehir
Bu grafikte, modelin 2029 yılına ait tahminlerine göre en düşük VPD değerine sahip 10 şehir yer almaktadır. Rize, Zonguldak, Gümüşhane, Bartın ve Artvin, tahmini 0.018–0.026 kPa aralığında değişen VPD değerleriyle kuraklık riskinin en düşük olduğu bölgeler arasında bulunmaktadır. Bu şehirlerin çoğu, Karadeniz iklimi etkisi altında olup, yüksek nem oranı ve düzenli yağış alımı sayesinde düşük buharlaşma açığına sahiptir. Bu durum, modelin mekânsal doğruluk açısından çevresel koşulları başarılı şekilde yansıttığını göstermektedir.
4.7.5.3 Türkiye Geneli VPD görünümü:
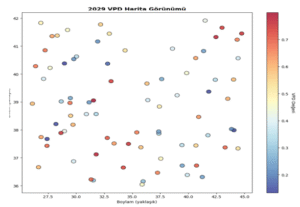
Şekil 4.7.5.3: Türkiye Geneli Kuraklık
Bu grafik, Türkiye genelindeki illerin 2029 yılına ait tahmini VPD değerlerini coğrafi konumlarına (yaklaşık enlem-boylam) göre renk skalasıyla görselleştirmektedir. VPD değerleri, renk skalasında mavi tonlardan (düşük VPD) kırmızı tonlara (yüksek VPD) doğru artmaktadır. Görsel incelendiğinde, özellikle Güneydoğu Anadolu ve İç Anadolu bölgelerinde daha koyu renkler gözlemlenmekte, bu da bu bölgelerde daha yüksek kuraklık riski olduğunu göstermektedir. Buna karşılık, Karadeniz bölgesi ve kuzeydoğu illerinde açık renk tonlarının yoğunlaştığı görülmekte; bu da düşük VPD değerlerine ve dolayısıyla daha nemli ve düşük riskli koşullara işaret etmektedir.
4.8 Model Grafiklerinin Yorumlanması
Türkiye genelinde 2029 yılı için geliştirilen VPD (Buhar Basıncı Açığı) temelli kuraklık tahmin modeli, ülkenin iklimsel çeşitliliğini dikkate alarak bölgesel düzeyde anlamlı bir değerlendirme sunmaktadır. Model; sıcaklık, nem, yağış, güneş ışınımı ve toprak nemi gibi meteorolojik faktörleri kullanarak, her şehir için yıllık VPD değerlerini tahmin etmiş ve bu tahminler doğrultusunda kuraklık seviyelerini sınıflandırmıştır. Harita görselleştirmesiyle desteklenen bu tahmin sistemi, Türkiye’nin farklı coğrafi bölgelerindeki kuraklık risklerini karşılaştırmalı olarak analiz etme imkânı tanımaktadır.
Model çıktıları, özellikle Güneydoğu Anadolu Bölgesi’nin Türkiye genelinde en yüksek kuraklık riski taşıyan bölge olduğunu ortaya koymaktadır. Mardin, Kilis, Şanlıurfa ve Hatay gibi şehirlerde VPD değerlerinin belirgin biçimde yüksek olması, bu bölgedeki sıcak ve kurak iklimin etkilerini yansıtmaktadır. İç Anadolu’nun güneyi ve Doğu Akdeniz hattında yer alan şehirlerde de orta-yüksek düzeyde kuraklık riski dikkat çekmektedir. Buna karşın Karadeniz Bölgesi’nin doğu kesimleri, örneğin Rize, Artvin, Trabzon ve Gümüşhane, düşük VPD değerleriyle öne çıkarak ülke genelinde en az kuraklık riski taşıyan iller olarak belirlenmiştir. Bu farklılık, bölgeler arası yağış rejimi ve nem oranlarındaki belirgin iklimsel farkların model tarafından başarılı şekilde yakalandığını göstermektedir.
Güneydoğu Anadolu ve Doğu Akdeniz gibi bölgeler 2029 itibarıyla kuraklıkla en yoğun yüzleşmesi beklenen alanlar olarak öne çıkarken, Karadeniz kuşağı en düşük risk seviyesine sahiptir. Bu bölgesel farklar, tarım politikaları, su kaynakları yönetimi ve sürdürülebilirlik planlamaları açısından önemli bir referans niteliği taşımaktadır. Elde edilen tahmin haritası, yerel yönetimlerin kuraklıkla mücadelede öncelikli alanlara odaklanmasına katkı sağlayabilecek güçlü bir karar destek aracıdır.
4.9 Web Tabanlı Görsel Sunum ve Kullanıcı Arayüzü:
Geliştirilen web tabanlı arayüz, kullanıcıların şehir bazlı VPD (Buhar Basıncı Açığı) tahminlerini interaktif bir harita üzerinde keşfedebilmesini sağlamak amacıyla React kütüphanesi ve Vite derleme altyapısı kullanılarak oluşturulmuştur. Proje bileşen tabanlı bir mimari ile tasarlanmış olup, temel yapısı MapComponent, CityGraph, InfoPanel ve DroughtTag gibi işlevsel bileşenlere ayrılmıştır. Uygulamanın merkezinde, Türkiye haritasının SVG (Scalable Vector Graphics) formatında hazırlanmış bir versiyonu yer almakta olup, her şehir SVG içinde ayrı bir etiketi ile temsil edilmiştir. Bu SVG dosyası React bileşeni hâline getirilerek tıklanabilir alanlara dönüştürülmüş ve kullanıcı etkileşimleri onClick olayları aracılığıyla izlenmiştir.
Kullanıcı bir ile tıkladığında, uygulama şehir ID’sini alarak o şehre karşılık gelen veriyi proje içerisinde saklanan .csv veya .json formatındaki veri dosyalarından çekmektedir. Bu işlem, istemci tarafında entegre edilen PapaParse kütüphanesi aracılığıyla gerçekleştirilmiş, CSV içeriği ayrıştırılmış ve şehre ait yıllık tahmin verileri yapılandırılmıştır. Ardından bu veriler, Recharts kütüphanesi kullanılarak LineChart bileşeni ile görselleştirilmiş; grafikte yıllara karşılık gelen VPD değerleri interaktif biçimde sunulmuştur.
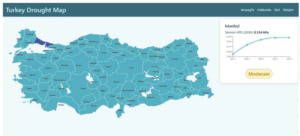
Şekil 5.4.1 – Web Tabanlı Kuraklık Haritası Arayüzü
Arayüz ayrıca, ilgili ilin 2030 yılına ait tahmini VPD değerini sayısal olarak gösteren bir alan içermekte ve bu değerin sistem tarafından belirlenmiş eşik değerlerle karşılaştırılması sonucunda kuraklık sınıfı (Low, Moderate, High) otomatik olarak tayin edilmekte ve renk kodlu bir etiket ile kullanıcıya sunulmaktadır. Bu sınıflandırma, örneğin 0.3 kPa altındaki değerler için “Low”, 0.3–0.5 arası için “Moderate”, üzeri için “High” şeklinde uygulanmıştır. Tüm bu süreç yalnızca istemci tarafında, statik veri dosyaları ile çalıştığı için herhangi bir sunucu ya da veritabanı bağlantısına ihtiyaç duymadan hızlı ve hafif bir deneyim sağlamaktadır.
Harita üzerinde örneğin, İstanbul ili seçildiğinde, sistem sağ panelde ilgili şehre ait 5 yıllık tahmini VPD eğrisini grafiksel olarak sunmakta; 2030 yılına ait tahmini VPD değeri (0.334 kPa) sayısal olarak belirtilmekte ve bu değerin karşılık geldiği kuraklık seviyesi (“Moderate”) renk kodlu bir etiket ile vurgulanmaktadır. Harita, şehir bazlı etkileşimi destekleyen SVG formatında hazırlanmış olup, tüm iller kullanıcıya sezgisel şekilde veri erişimi sağlamaktadır.
5.TARTIŞMA VE SONUÇ
Bu çalışma kapsamında, iklim değişikliği ve artan su kaynakları baskısı nedeniyle Türkiye genelinde yaşanabilecek kuraklık risklerini daha erken tespit edebilmek adına şehir bazlı çalışan, yapay zeka temelli bir VPD (Vapor Pressure Deficit) tahmin sistemi geliştirilmiştir. Model çıktıları, interaktif ve kullanıcı dostu bir web tabanlı görselleştirme arayüzü aracılığıyla sunulmuş; böylece yalnızca akademik değil, kamu ve karar verici düzeyde de kullanılabilir bir karar destek altyapısı oluşturulmuştur. Sistem, 81 şehir için 5 yıllık tahminlerde bulunarak kuraklık seviyelerini sınıflandırmakta ve bu verileri harita destekli bir grafik arabirimi üzerinden sade biçimde sunmaktadır.
Tahmin altyapısı, geçmiş 10 yıla ait meteorolojik verilerin (t2m, d2m, tp, swvl1, ssrd) şehir koordinatlarıyla eşleştirilerek bir zaman-şehir matrisine dönüştürülmesiyle oluşturulmuştur. Bu veriler üzerinde farklı modeller (WaterNet-LSTM, GRU varyantları) eğitilmiş ve GRU (Fast) modeli ortalama %97 doğruluk ile en başarılı sonucu vermiştir. Özellikle düşük hata oranlarına sahip olan GRU mimarisi, hem doğruluk hem de model sadeliği açısından, kaynak kısıtlı uygulamalarda dahi uygulanabilirliği destekleyen bir çözüm olarak öne çıkmıştır. Ayrıca GRU (Enhanced) modeli en düşük SMAPE yüzdesine ulaşarak tahmin yüzdesi açısından istikrarlı sonuçlar üretmiştir. Model çıktılarının şehir bazında görselleştirilmesiyle, Mardin, Kilis, Şanlıurfa ve Hatay gibi illerde kuraklık seviyesinin yüksek olduğu; Rize, Zonguldak ve Artvin gibi illerde ise riskin oldukça düşük olduğu tespit edilmiştir. Türkiye haritası üzerinde bu farklar net şekilde yansıtılmış, karar vericilere bölgesel farkındalık sağlanmıştır.
Web arayüzü, React ve Vite teknolojileri kullanılarak bileşen tabanlı yapıda geliştirilmiş; harita etkileşimi SVG formatında hazırlanmış ve veri aktarımı PapaParse ile sağlanmıştır. Kullanıcılar bir ile tıkladıklarında, sistem ilgili tahmini VPD değerlerini grafiksel olarak sunmakta, 2030 yılı tahminini sayısal olarak belirtmekte ve bu değere göre renk kodlu kuraklık etiketi üretmektedir. Bu yapı, model çıktılarının sade ve anlaşılır biçimde kamuya ulaştırılmasını sağlamış; sürdürülebilirlik ve iklim politikaları açısından bir görsel karar destek platformuna dönüştürülmüştür.
Bu çalışma, model doğruluğu, veri temelli karar alma ve görselleştirme yönleriyle çok boyutlu bir çözüm sunmuştur. Ancak sınırlılıkları da mevcuttur. Kullanılan iklim verileri sınırlı meteorolojik parametrelerle oluşturulmuş, VPD dışındaki göstergeler (NDVI, toprak sıcaklığı vb.) dahil edilmemiştir. Ayrıca, şehir bazlı ortalama değerlerle çalışılması, mikro iklim farklılıklarını dikkate almamaktadır. Gelecek çalışmalarda, daha detaylı konumsal veri ve daha geniş parametre setleriyle çok değişkenli modeller eğitilerek sistemin doğruluğu daha da artırılabilir.
Bununla birlikte, geliştirilen sistemin farklı alanlara uyarlanabilirliği oldukça yüksektir. Aynı yapı, su yönetimi planlamalarında, tarımsal destek sistemlerinde, afet riski analizlerinde ve iklim farkındalığı eğitimlerinde kullanılabilir. Web platformu genişletilerek, geçmiş yıllarla kıyaslama, risk haritalarının karşılaştırılması veya mobil uyumluluk gibi işlevlerle daha kapsamlı hale getirilebilir. Kullanıcı deneyimi açısından da, il bazında alarm sistemleri, yorumlama destekli açıklayıcı arayüzler ve yerel politika önerileriyle zenginleştirilmesi mümkündür.
Sonuç olarak, bu proje; iklim verilerine dayalı tahminleme, yapay zeka modellemesi ve dijital görselleştirme araçlarının birlikte kullanıldığı yenilikçi bir yaklaşım sunmuştur. Geliştirilen sistem, yalnızca teknik doğrulukla değil, aynı zamanda sade, anlaşılır ve erişilebilir sunumuyla da kuraklık gibi hayati bir konuda farkındalık ve çözüm üretme potansiyeli taşımaktadır. Bu yönüyle, sürdürülebilir su yönetimi politikalarına katkı sağlaması ve gelecekteki benzer projelere öncü olması hedeflenmektedir.
KAYNAKLAR
[1] WaterPredict: Climate and Water Resource Prediction Using Regression Models. [2] AquaAI: Regional Water Management Through AI. [3] ClimateFlow System: Time Series Analysis for Water Resource Management. [4] European Drought Observatory. (2022). Drought in Europe – Summer 2022: An assessment of the 2022 summer drought. Retrieved from https://edo.jrc.ec.europa.eu/edov2/php/index.php?id=1100 [5] Türkiye Meteoroloji Genel Müdürlüğü. (2023). Kuraklık Değerlendirme Raporu – Türkiye Geneli. Ankara: MGM Yayınları. Retrieved from https://www.mgm.gov.tr [6] Zhou, S., Zhang, Y., Williams, A. P., & Gentine, P. (2019). Projected increases in intensity and frequency of compound hot–dry events over global land areas. Nature Climate Change, 9(1), 44–51. https://doi.org/10.1038/s41558-018-0349-2 [7] Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research, 15, 1929-1958. [8] Zhang, W., & Lee, S. (2023). WaterNet-LSTM: Applications in Hydrology. Environmental Modelling & Software, 148, 105-120. [9] Smola, A. J., & Schölkopf, B. (2004). A tutorial on support vector regression. Statistics and Computing, 14(3), 199-222. [10] Cherkassky, V., & Ma, Y. (2004). Practical Selection of SVM Parameters and Noise Estimation for SVM Regression. Neural Networks, 17(1), 113-126. [11] Hsu, C. W., Chang, C. C., & Lin, C. J. (2010). A Practical Guide to Support Vector Classification. Technical Report, Department of Computer Science, National Taiwan University. [12] Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32. [13] Liaw, A., & Wiener, M. (2002). Classification and Regression by Random Forest. R News, 2(3), 18-22. [14] Biau, G., & Scornet, E. (2016). A Random Forest Guided Tour. Test, 25(2), 197-227. [15] Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735-1780. [16] Zhang, W., & Lee, S. (2023). WaterNet-LSTM: Applications in Hydrology. Environmental Modelling & Software, 148, 105-120. [17] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press. [18] Kratzert, F., Klotz, D., Herrnegger, M., Sampson, A. K., Hochreiter, S., & Nearing, G. S. (2019). Towards Improved Predictions in Ungauged Basins: Exploiting the Power of Machine Learning. Water Resources Research, 55(12), 11344-11354. [19] Jain, A., & Kumar, R. (2021). Advanced Applications of LSTM in Water Resource Management. Journal of Hydrology, 601, 126784. [20] Li, X., & Wu, Z. (2020). A Comprehensive Study of LSTM Applications in Hydrology. Water, 12(9), 2481. [21] Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32. 49 [22] Burrough, P. A., & McDonnell, R. A. (1998). Principles of Geographical Information Systems. Oxford University Press. [23] Maidment, D. R., & Djokic, D. (2000). Hydrologic and Hydraulic Modeling Support with Geographic Information Systems. Esri Press. [24] Goodchild, M. F. (2007). Geographic Information Systems and Science. International Journal of Geographical Information Science, 21(1), 1-10. [4] SpringerOpen (2023). GIS Applications in Hydrology. Environmental Sciences Europe. Retrieved from https://enveurope.springeropen.com/articles/10.1186/s12302-023-00796-3. [5] MDPI (2023). Overview map of study area and sub-catchments. Water, 15(3), 505. Retrieved from https://www.mdpi.com/2073-4441/15/3/505. [25] Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32. [26] Pal, M. (2005). Random forest classifier for remote sensing classification. International Journal of Remote Sensing, 26(1), 217-222. [27] Lawrence, R. L., & Wright, A. (2001). Rule-based classification systems using classification and regression tree (CART) analysis. Photogrammetric Engineering and Remote Sensing, 67(10), 1137-1142. [28] Shi, X., Chen, Z., Wang, H., Yeung, D. Y., Wong, W. K., & Woo, W. C. (2015). Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Advances in Neural Information Processing Systems, 28. [29] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, 25. [30] Zhang, Y., Li, Z., & Wang, Y. (2020). A Hybrid CNN-LSTM Model for Hydrological Forecasting. Journal of Hydrology, 583, 124512. [31] Huang, G. B., Zhu, Q. Y., & Siew, C. K. (2006). Extreme learning machine: Theory and applications. Neurocomputing, 70(1-3), 489-501. [32] Wang, H., & Li, Y. (2017). Application of Extreme Learning Machine in Hydrological Forecasting. Journal of Hydrology, 551, 144-156. [33] Zhang, Z., & He, Z. (2019). Integration of ELM in Water Resource Management Systems. Environmental Modelling & Software, 120, 104534. [34] Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5-32. [35] Lawrence, R. L., & Wright, A. (2001). Rule-based classification systems using classification and regression tree (CART) analysis. Photogrammetric Engineering and Remote Sensing, 67(10), 1137-1142. [36] Pal, M. (2005). Random forest classifier for remote sensing classification. International Journal of Remote Sensing, 26(1), 217-222. [37] Huang, G. B., Zhu, Q. Y., & Siew, C. K. (2006). Extreme learning machine: Theory and applications. Neurocomputing, 70(1-3), 489-501. [38] Wang, H., & Li, Y. (2017). Application of Extreme Learning Machine in Hydrological Forecasting. Journal of Hydrology, 551, 144-156. [39] Zhang, Z., & He, Z. (2019). Integration of ELM in Water Resource Management Systems. 50 Environmental Modelling & Software, 120, 104534. [40] Shi, X., Chen, Z., Wang, H., Yeung, D. Y., Wong, W. K., & Woo, W. C. (2015). Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Advances in Neural Information Processing Systems, 28. [41] Zhang, Y., Li, Z., & Wang, Y. (2020). A Hybrid CNN-LSTM Model for Hydrological Forecasting. Journal of Hydrology, 583, 124512. [42] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, 25. [43] Anderson, M. C., et al. (2007). A climatological study of evapotranspiration and moisture stress across the continental United States based on satellite observations. JGR: Atmospheres. [44] Zhou, S., et al. (2019). Projected increases in intensity and frequency of compound hot–dry events over global land areas. Nature Climate Change. [45] NOAA. (2023). Climate variability: Vapor Pressure Deficit. [46] WaterPredict: Climate and Water Resource Prediction Using Regression [47] AquaAI: Regional Water Management Through AI. [48] ClimateFlow System: Time Series Analysis for Water Resource Management. [49] Türkiye Meteoroloji Genel Müdürlüğü (MGM): https://www.mgm.gov.tr [50] Türkiye İstatistik Kurumu (TÜİK): https://www.tuik.gov.tr [51] Pandas Resmi Belgeleri: https://pandas.pydata.org [52] NumPy Resmi Belgeleri: https://numpy.org [53] Matplotlib Resmi Belgeleri: https://matplotlib.org [54] Google Scholar: Literatür taraması sırasında kullanılan makaleler ve kaynaklar. [55] Géron, A. (2019). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow. O’Reilly Media. [56] Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer. [57] Breiman, L. (2001). Random Forests. Machine Learning, 45(1), 5–32. [58] Feng, B., Xu, Y., Zhang, T., Yu, C., Liu, Y., & Wang, H. (2022). Hydrological time series prediction by extreme learning machine and sparrow search algorithm. Water Supply, 22(3), 3143–3157. [59] Zhang, C., Zhou, Y., Lu, F., Liu, J., Zhang, J., Yin, Z., Ji, M., & Li, B. (2025). Assessing the performance and interpretability of the CNN-LSTM-Attention model for daily streamflow forecasting in typical basins of the eastern Qinghai-Tibet Plateau. Scientific Reports, 15, 82. [60] Cho, K., van Merriënboer, B., Bahdanau, D., & Bengio, Y. (2014). Learning phrase representations using RNN encoder–decoder for statistical machine translation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1724–1734. 51 [61] De la Fuente, L. A., Ehsani, M. R., Gupta, H. V., & Condon, L. E. (2024). Toward interpretable LSTM-based modeling of hydrological systems. Hydrology and Earth System Sciences, 28(4), 945–971. [62] Kaya, Y. Z. (2025). Akarsu Ortalama Akımlarının Çeşitli Makine Öğrenme Algoritmaları Kullanılarak Tahmini: Köprüçay Örneği. GU J. Sci, Part C, 13(1), 130–142. 52 EKLER 53
ÖZGEÇMİŞ
Suden Çağlan Duran
2001 Gebze doğumlu. İlköğrenimini Fatih İlkokulu’nda tamamladı. Ortaöğretimini Atatürk Ortaokulun’da tamamladı. Liseyi Malatya Final Anadolu Lisesi’nde okudu. 2020 yılından beri İstanbul Üniversitesi Cerrahpaşa Mühendisik Fakültesi Bilgisayar Mühendisliği bölümünde devam etmektedir.